
https://www.youtube.com/watch?v=6SlgtELqOWc&list=PLC1qU-LWwrF64f4QKQT-Vg5Wr4qEE1Zxk&index=8
## CPU vs GPU

- CPU (Central Processing Unit)
=> 더 적은 core 수를 가진다 (좀 더 적은 core 수로 연속적인 일을 처리하는데 CPU가 자주 쓰임)
=> GPU에 비해 비교적 적은 사이즈로 제작이 되며, RAM에서 메모리를 가져다가 사용하게 된다.
=> 각 core는 더 빠르며 연속적 처리 (sequential tasks)를 처리하는데 특화되어 있다.
- GPU (Graphics Processing Unit)
=> 수천개의 core 수를 가진다
=> 각 core는 더 느리지만 동시에 일을 수행(parallel tasks)을 처리하는데 특화되어 있다.
=> 개별적인 RAM을 가지며, RAM 사이에 cache 시스템이 존재한다.

=> 위와 같이 GPU에서는 두 행렬곱 사이에 동시연산이 가능하다는 점에서 강력하다고 볼 수 있다.
=> GPU의 경우 행렬곱 동시연산에 특화되어 있다는 점에서 딥러닝에서 많이 사용되나, 따로 쿨러도 있고 파워도 많이 잡아먹는다는 단점이 있다.
# GPU programming으로 많이 사용되는 3가지
=> CUDA (NVIDIA only)
=> OpenCL
=> Udacity
# GPU 학습 시 생길 수 있는 문제 및 해결책
=> CPU와 GPU는 물리적으로 분리되어 있다. 따라서 딥러닝 시 모델과 가중치는 GPU RAM에 상주하는 반면 실제 train data는 저장장치(HHD, SSD 등)에 위치하게 된다.
=> 위 문제로 인해 디스크에서 data를 읽어오는 과정에서 bottle-neck 현상이 일어날 수 있다
- 데이터 전송 과정에서 bottle-neck 현상 해결책
=> data-set이 작다면 RAM에 미리 올려놓기
=> HHD보다는 SSD를 사용하여 데이터 읽는 속도 향상
=> CPU의 multi-thread를 사용하여 prefatch된 data를 사용
========== ========== ========== ========== ========== ========== ========== ==========
## Deep Learning Framework

위 영상은 2017년 강의 자료니까 지금은 분명 다른 framework들도 많이 생겼을 것이다.
하지만 아직까지도 PyTorch와 TensorFlow가 메인 프레임워크 인 것으로 알고 있다.
딥러닝 프레임워크를 통해 기대할 수 있는 효과는 아래와 같다.
1. Computational graph를 쉽게 build
2. Gradient 계산 용이
3. GPU에서 효과적으로 딥러닝 학습 가능

=> Computational Graphs를 위해 Numpy를 사용했다고 가정해보자 (맨 왼쪽 사진)
위와 같은 방법을 사용하면 Backward pass 연산을 단계적으로 계산해야만 한다.
또한 GPU 연산을 이용하지 못한다(Numpy는 CPU에서 계산하는 것만 지원함). 그래서 TensorFlow나 PyTorch 와 같은 framework를 사용하려고 하는 것이다.
========== ========== ========== ========== ========== ========== ========== ==========
## PyTorch

=> PyTorch는 3 가지 추상화 레벨이 나누어져 있다.
1. Tensor : 다차원 배열이며, GPU에서 돌아가게끔 만든 배열이다. ndarray, GPU에서 구동한다.

=> 랜덤 데이터 (randn)를 생성하고 gradient descent까지 실행한다. 이때 numpy가 아닌 torch에서 제공되는 tensor dtype를 적용한다. (GPU에서 구동 가능)
=> dtype = torch.cuda.FloatTensor를 적용해주면 torch의 tensor로 인식하며 GPU 구동이 가능해지게 된다. (cuda가 있으면 GPU에서 실행하라는 의미다)
2. Variable : computational graph의 노드, data와 gradient를 저장한다.

=> x.data : Tensor
=> x.grad : computational grah에서 tensor를 이용해 계산한 gradient
=> x.grad.data : 위의 gradient들을 담은 tensor
=> 빨간색/파란색 박스를 통해 variable이 requires_grad를 체크할 수 있는데, true일때 해당 데이터에 대한 gradient를 구하곘다는 것이다.
3. Module : neural network layer로 어떤 상태나 업데이트 중인 weight를 저장한다. NN에서의 하나의 layer라고 생각하면 된다.
* 여러 operation 들
1. nn : PyTorch의 상위레벨 wrapper. (Tensor-Flow의 keras와 같은 역할)

PyTorch의 경우 TensorFlow와 다르게 grapht가 dynamic grapht이기 때문에, training을 시킬 때마다 매번 새로운 그래프를 구성한다.

또한 이와 같이 모듈을 새로 만들어주고, 내가 만든 모델을 이용하여 학습을 진행할 수도 있다.
별개로 PyTorch에는 이미 여러 모델들이 구현되어 있다.

=> 같은 코드에서 optimizer를 통해 learning rate를 쉽게 정할 수도 있다.
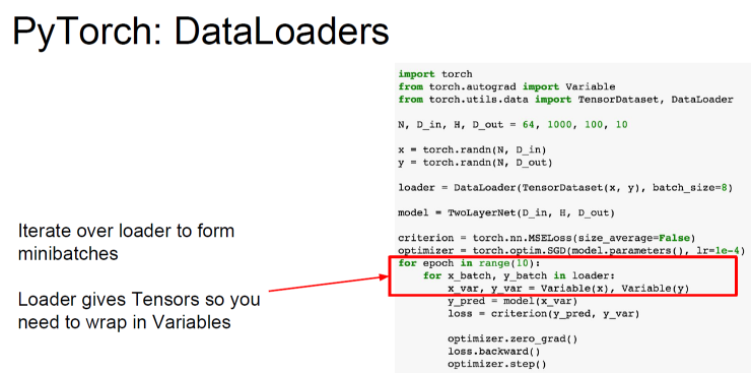
=> DataLoader로 data set을 쉽게 불러올 수도 있다. 미니배치, 셔플, 멀티스레딩을 알아서 해준다.
========== ========== ========== ========== ========== ========== ========== ==========
## PyTorch vs TensorFlow
* TensorFlow
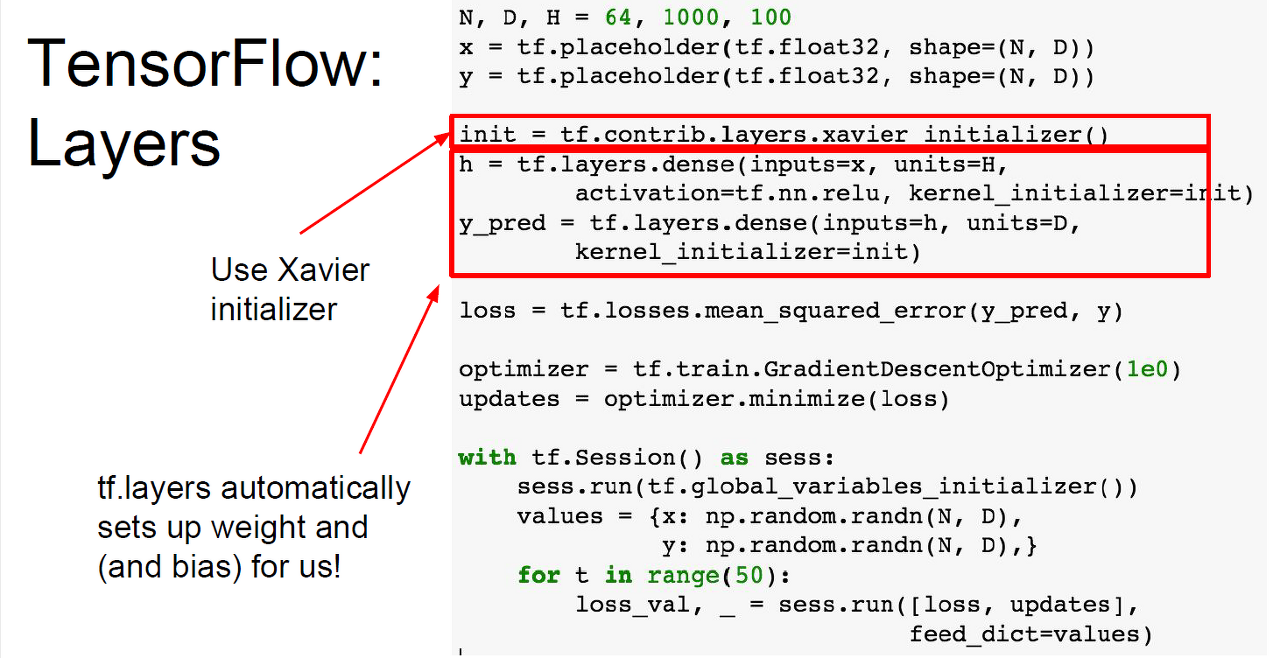
=> NN(Neural Network)를 먼저 정의한 이후 run을 통해 training을 시켜야 한다. 그렇기 때문에 graph의 형태가 굉장히 static하다는 특징을 가진다.
Static grapht의 특징으로는 한번 model을 구성해 놓으면 재사용이 쉽고, run을 하기 전에 optimization 과정을 진행할 수 있다.
=> 위 코드를 보면 처음 NN을 만들고 placeholder에 input과 weight 값들을 넣어주게 된다.
이후 xavier에 의해 weight의 초기화 값을 설정해주고, y_pred를 이용해서 자동적으로 weight 값이 바뀌도록 설정해준다.
* Keras

=> Keras란 TensorFlow에서 제공하는 high level wrapper 이다. 직관적으로 모델을 만들 수 있도록 구성되어 있다.
* TensorFlow vs PyTorch

=> TensorFlow : static graph로 처음애 구성한 computational graph 를 매 iteration 마다 재사용 한다.
=> PyTorch : dynamic graph로 매 iteration 수행시마다 새롭게 computational graph를 생성한다.
Static graph
1. 그래프 최적화로 동일한 graph를 재사용하기에 optimization에 유리하다. 초기에는 최적화 과정이 느릴 수도 있지만, 반복이 진행
2. 전체 그래프의 자료 구조를 파일 형태로 저장이 가능하다. 그렇기 때문에 코드 원본에 접근하지 않고 해당 파일에만 접근해도 구동이 가능하다.
3. 조건부 연산 그래프는 따로 만들어야 되는 단점이 있다.
Dynamic graph
1. Forward pass 할때마다 새로운 그래프를 구성한다. 그렇기에 최적화는 어렵다.
2. 모델을 재사용하기 위해서는 항상 원본 코드가 필요하다.
3. 하지만 조건부 연산 (python if 문) 등을 이용하여 구성할 수 있기에 코드가 깔끔하고 작성하기 쉽다는 장점이 있다.

=> 마지막으로 강의에서는 TensorFlow가 두루두루 사용하기에는 편할 수도 있지만. 연구 등을 위해서는 PyTorch가 나을 수도 있다고 권장한다. 하지만 어떠한 프레임워크를 사용해야 되는지는 상황에 따라 결정하면 된다.
'Nvidia > CS231n' 카테고리의 다른 글
| CS231n 7강 (2) | 2024.01.05 |
|---|---|
| CS231n 6강 (1) | 2023.12.19 |
| CS231n 5강 (1) | 2023.12.15 |
| CS231n 4강 (0) | 2023.12.11 |
| CS231n 3강 (0) | 2023.12.07 |