
https://www.youtube.com/watch?v=bNb2fEVKeEo&list=PLC1qU-LWwrF64f4QKQT-Vg5Wr4qEE1Zxk&index=5
## CNN
* CNN이 생겨난 배경
이전 강의때 나왔던 NN (Neural Network)를 통해 해결하기 어려웠던 문제들을 풀어내기 시작했다.
하지만 여러 겹을 쌓아서 해결하려는 multi-layered NN은 영상에 바로 적용하기 어렵다는 단점이 있다.
Image Data는 Spatial structure (공간적 구조), 즉 세로/가로/채널 의 3차원 형상을 가지고 있다.
하지만 위와 같이 NN을 사용하게 되면 input data가 1차원 배열로 바꿔주는 과정에서 데이터의 형상이 무시된다는 한계점이 있다.
예를 들어 글자 '5'가 그려진 이미지를 학습한다고 할때, 글자의 크기가 달라지거나 회전되는 등의 작은 변형이 생겨도 모두 새로운 데이터로 인식하게 된다.
따라서 모든 변형을 가정한 데이터를 넣어줘야 좋은 결과를 가질텐데 이는 불가능에 가깝다.
그렇기에 CNN (Convolutional Neural Networks) 의 개념이 나타나게 되었다.
======= ======= ======= ======= ======= ======= ======= ======= =======
* CNN의 쓰임새

=> 이미지 분류, 이미지 검색

=> Detection, Segmentation(각 픽셀에 라벨링)

=> Lidar를 통한 자율 주행

=> face recognition, video recognition

=> pose recognition, 게임 산업

=> Image captioning (ex Dall-E)
======= ======= ======= ======= ======= ======= ======= ======= =======
* CNN 용어
일단 FC-layer와 다르게 CNN은 Convolutional layer와 pooling layer로 구성되어 있다.
CNN 원리에 들어가기 앞서 용어들을 먼저 살펴보자면
NN에서 사용되는 Neuran은 CNN에서는 아래와 같은 용어들로 사용되고 있다.
neuran = filter = kernal
3개의 단어는 모두 혼용되며 사용되고 있긴 하지만, 정확하게 따지자면
- kernal : 입력에 곱하는 가중치
- filter : 뉴런의 개수
또한 padding과 stride라는 개념이 등장한다.

=> Padding이란 Conv 연산을 수행하기 전 가짜 픽셀을 가장자리에 넣어주는 것이다.
Padding 시 채워야 하는 값은 지정해줘야 하는 hyperparameter에 속하게 된다.
특히 의미없는 0의 값으로 padding을 하는 경우는 zero padding이라고 한다.
Padding을 사용하게 되면 아래에서 설명할 Conv layer를 지날 때마다 지속적으로 data가 줄어드는데, 특히 중앙부의 data가 더 많이 반영될 수 밖에 없는 구조이다.
그렇기 때문에 가장자리의 중요한 정보 또한 반영하기 위해서 Padding을 실시하는 것이다.

=> stride는 input data에 filter를 적용할 때 이동 간격을 조절해주는 매개 변수이다.

=> Stride를 잘 설정해야 되는 것이, 위에서 보이는 것처럼 input data의 spatial 을 넘겨버리면 안되기 때문에 padding과 stride를 잘 적용하여 모든 픽셀 값이 다 적용되어지게 해야한다.
======= ======= ======= ======= ======= ======= ======= ======= =======
* CNN 원리
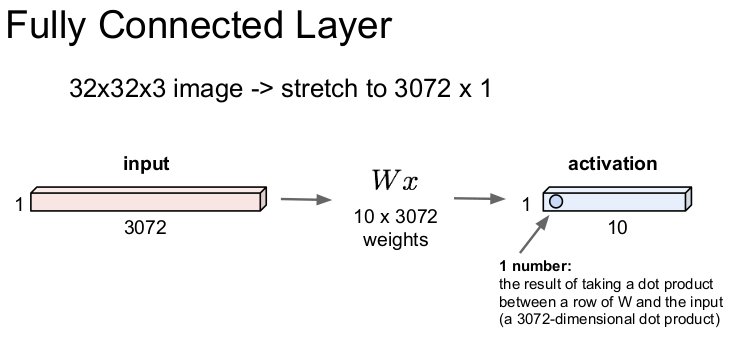
=> 기존 FC layer (Fully Connected Layer)의 경우 벡터를 펴서 내적 연산을 하는 방식이다.
즉, 32*32*3 의 이미지가 있다면 이를 1차원 구조인 3072*1로 만들어서 가중치 W와 같이 처리되며 결과론적으로 1*10의 activation layer에 1개의 숫자를 출력하게 된다.
이와 다르게 CNN의 경우 기존의 structure를 보존하면서 계산을 하게 된다.

=> CNN의 경우 32*32*3의 이미지를 사진 크기 그대로 원형을 보존한다.

=> 그리고 W(weight) 값은 오른쪽 파란색과 같은 filter가 된다.
여기서 주의할 점은 가로, 세로의 크기는 input의 크기보다 크지만 않으면 되지만, filter의 depth는 항상 input 값과 같아야 한다. 고로 3의 값을 가짐.
여기서 depth는 RGB 3 채널을 의미한다.
해당 filter는 input image에서 슬라이딩 되며 내적을 구하게 되는데, 이를 convolve 라고 한다.

=> 즉 위와 같이 왼쪽 상단부터 모든 부분마다 convolve 되면서 점곱을 해주는 과정을 거친다고 보면 된다.
그리고 나서 b(bias)를 더해주는 것이다.
점곱을 해주는 과정에 대해서는 아래와 같다.
5 * 5 * 3 = 75 dimensional dot product + 1 (bias)

=> 5 * 5 의 filter를 지속적으로 convolve 하면 28 * 28 * 1 크기의 output이 생성된다.
계산법을 편하게 하려면
(input 가로) - (filter 가로) + 1
... 세로도 마찬가지의 연산. 즉 32 - 5 + 1 = 28
이렇게 나타나게 되는 파란색 output의 값을 activation map이라고 한다.
(feature map과 혼용되어 사용되기도 하는것 같은데, feature map은 Convolution 연산으로 만들어진 matrix를 의미하며, activation map은 feature map matrix에 activation function을 적용한 결과이다. 즉 Conv layer의 최종 output은 activation map 이다)
위 사진의 경우 filter가 1개라고 가정한 것이다.
만약 5*5*3 크기를 가진 filter 가 6개가 있다고 가정해보자.

=> 그럼 위 그림과 같이 28*28*1 size인 activation map이 총 6개가 생성이 된다.
이러한 상황에서 계속적으로 Conv layer를 통과한다고 해보자.

처음에는 32*32*3 size에 6개의 5*5*3의 filter를 지나서 28*28*6 size의 activation map이 만들어졌다.
두번째에는 28*28*6 size에 10개의 5*5*5 filter를 지나서 24*24*10 size의 activation map이 만들어졌다.
이런 식으로 연산이 진행이 된다.
그러면 언제까지 Conv layer를 계속 거쳐야 할까? -> 만족할만한 결과값이 나올때까지...
또한 위에서 언급했던 Padding과 Stride 값 또한 잘 설정하여 위의 activation map을 이끌어야 한다.
Output size는 (N - F ) / stride + 1 (N은 이미지 크기, F는 필터 크기) 의 공식을 가진다.
Padding 을 사용해야 계속되는 Convolution 과정에서 사진의 크기가 원본과 그대로 유지된다.
CNN 모델 디자인은 filter의 크기와 숫자, 그리고 stride를 통해 다양하게 선택될 수 있다.
CNN은 다음과 같은 특성을 가진다.
1. Locality (Local Connectivity)
=> 픽셀은 항상 일관된 순서를 가지며, 서로 인접한 픽셀끼리 영향을 준다. 그렇기에 주변 픽셀 값과 비교하여 픽셀 정보를 추측할 수 있다. 이 특성을 locality라 한다.
2. Shared Weighty
=> 동일한 계수를 가지는 filter를 전체 영상에 반복적으로 이용하기 때문에 변수의 수를 줄일 수 있다. 그렇기 때문에 topology 변화에 무관함.

Neuron 관점으로 보면 Convolutional layer는 locality를 가지는 뉴런과 같다.
Activation map은 입력 이미지의 국소적인 부분과 연결된다. 즉 CNN은 결국 특정 부분만 처리하는 neuron의 국소 지역 여러개가 모여서 전체적인 이미지를 보게 되는 형태와 흡사하다고 할 수 있다.
따라서 FC layer의 경우 이미지 전체의 특징 하나를 추출하기에, 이미지를 확대/ 축소 등등의 변형이 거치면 이미지의 특징을 찾기에 효과적이지 않다. 이러한 부분에 CNN이 강점을 두고 있기에 CNN이 사용되는 것이다.
======= ======= ======= ======= ======= ======= ======= ======= =======
* CNN 구조

=> 이와 같은 과정을 거치면서 CNN이 진행되게 된다.
여기서 Conv는 위에서 계속 설명했던 과정이고, ReLU 는 활성화 함수이다.
그러면 중간에 Pool 부분과, 마지막에 FC의 부분이 남게 된다.
Pooling layer란 activation map의 크기를 down-sampling하는 과정을 이야기한다.
그렇다면 위에서 padding을 통해 크기를 보존하려 했는데, 왜 이제와서 이미지를 줄인다는 것일까?
Padding은 크기 보존 뿐만 아니라 이미지의 부분적 특징을 살리기 위해 진행했었다.
하지만 여기서 Pooling layer는 이미지의 특정 부분을 잘라내는 것이 아니라, 사진 전체 부분을 유지한 상태로 픽셀만 줄이는 것이다. (게임 해상도를 줄이는 느낌(?))
Pooling layer를 하는 이유는, CNN이 진행됨에 따라 filter의 개수가 지속적으로 늘어나는데 이렇게 되면 activation map의 깊이가 너무 깊어지게 된다. 그러면 계산하는데도 오래 걸린다...
그렇기 때문에 다소 해상도를 포기하더라도 계산을 빠르게 하기 위해 activation map의 크기를 줄여주는 과정이 필요한 것이다.

=> Pooling layer에는 다양한 방법이 있지만 (ex>Average pooling), 보통 Max Pooling이 가장 많이 사용된다.
위와 같이 해당 filter 영역 내에서 가장 큰 값들만 pooling하는 방법이다.
단 이때는 stride를 잘 설정하여 filter가 서로 겹치지 않게 설정하는 것이 권장된다.
또한 크기를 의도적으로 줄이는 것이기 때문에 Pooling layer에서는 zero-padding을 하는 것이 일반적이지는 않다.
마지막으로 FC 부분, 즉 Fully Connected Layer만 남았다.
특정 이미지를 Convolution, ReLU 등의 활성화 함수 연산, Pooling 과정을 거치고 나서의 마지막 activation map들을 FC layer에 집어넣게 된다. 그러면 저번 강의때도 설명했지만 일반적인 인공 신경망과 같이 각각의 클래스마다 점수를 도출하여 score, loss 값 등등이 나오게 된다.
따라서 트렌드에 따라 조금씩 달라지긴 하지만, 일반적으로 CNN의 과정은 다음과 같다.
Conv - ReLU 의 과정 여러번 -> Pool -> Conv - ReLU 의 과정 여러번 -> Pool -> ...
-> 마지막 FC와 ReLU 여러번 -> SOFTMAX로 loss 값 산출
다만 트렌드에 따라서 Pool과 FC layer를 빼고 그냥 Conv 만 하는 경우도 있다고 한다.
'Nvidia > CS231n' 카테고리의 다른 글
| CS231n 7강 (2) | 2024.01.05 |
|---|---|
| CS231n 6강 (1) | 2023.12.19 |
| CS231n 4강 (0) | 2023.12.11 |
| CS231n 3강 (0) | 2023.12.07 |
| CS231n 2강 (0) | 2023.12.05 |