
https://www.youtube.com/watch?v=wEoyxE0GP2M&list=PLC1qU-LWwrF64f4QKQT-Vg5Wr4qEE1Zxk&index=6&t=1s
## 활성화 함수 (Activation Functions)

=> 활성화 함수는 딥러닝 과정 중 비선형성을 가해주는 중요한 부분이다.
만약 이러한 활성화 함수가 존재하지 않는다면 layer를 쌓는다고 해도 결국 single layer랑 다름이 없게 된다.

=> 위와 같은 무수히 많은 activation function이 존재한다. 하나씩 살펴보자
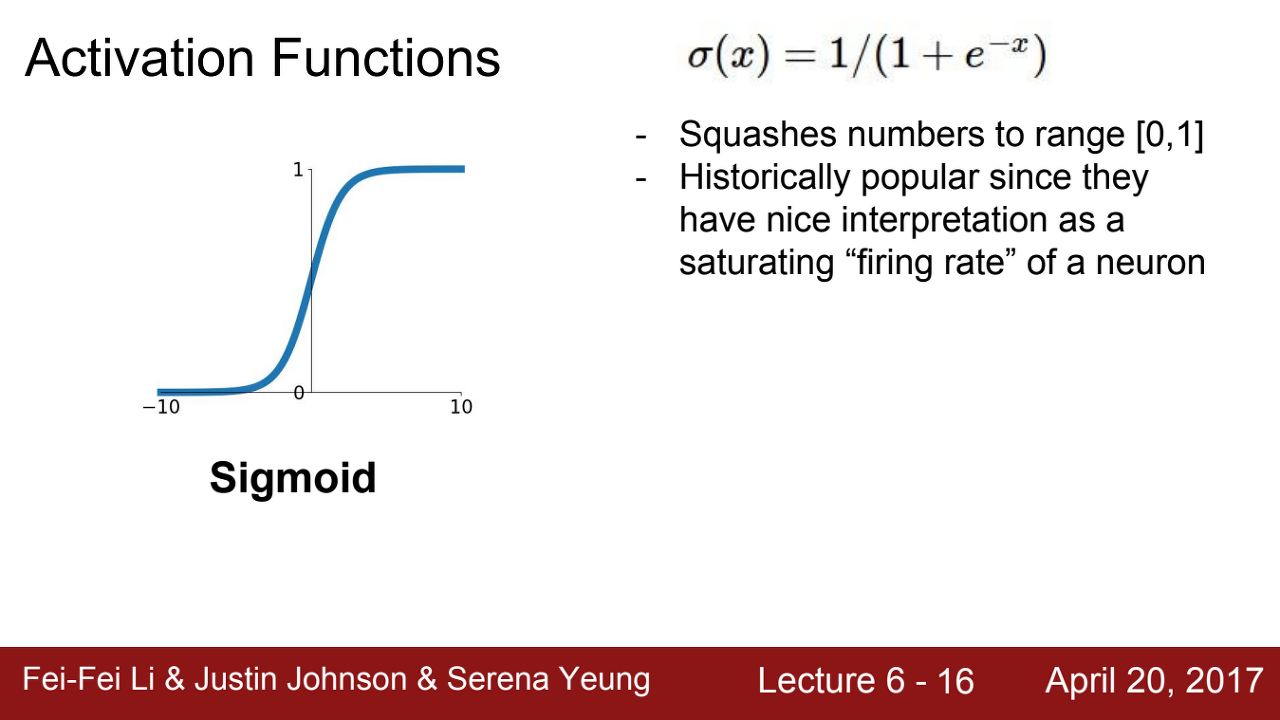
=> 0~1의 값을 가지게 되는 이 sigmoid 함수에는 다음과 같은 문제점들이 있다.
1. gradient를 없앤다 (Vanishing gradient)
=> x 값이 매우 크거나 작으면 기울기가 0에 수렴하게 된다.
2. zero-center
=> output 값이 항상 양수를 가질 수 밖에 없다. 따라서 계속해서 양수의 값만이 input이 되어 활성화 함수가 중첩되는 단점이 있다.
=> 이에 따라 W가 모두 양의 방향 또는 음의 방향으로 밖에 업데이트를 하지 못하기 때문에 zig zag path 형태를 가지며 비효율적이다.
3. exp() 연산은 많은 지원을 필요로 한다 -> 비싸다...
즉 활성화 함수로는 부적격.

=> 위 sigmoid 함수에 대한 개선점으로 나온 tanh(x) 함수.
하지만 이는 위 2번 문항인 zero-center 문제는 해결했지만, 여전히 1번 문항인 vanishing gradient 문제를 해결하지 못해서 활성화 함수로는 부적격

=> 그렇기 때문에 현재 가장 많이 사용되는 활성화 함수는 ReLU 이다.
f(x) = max(0.x)
x 값이 양수일 때는 입력값 x를 그대로 배출하기 때문에 vanihing gradient 문제를 어느 정도 해결함.
따라서 양의 영역에서는 W의 update가 가능해졌다.
또한 exp() 연산이 사라져서 sigmoid나 tanh 보다 계산 효율이 훨씬 좋다.
하지만 여전히 음의 영역에서는 vanishing gradient와 zero-centered output이 계속해서 나타난다는 한계가 있다.

이렇게 dead ReLU 현상이 나타날 수도 있다.
W initialization에서 dead ReLU에 속해지면 업데이트가 불가할 수도 있다.
또한 learning rate를 너무 크게 설정하는 경우에도 W가 너무 크게 비약해서 학습이 안되는 상황이 발생할 수도 있다.
실제로 학습을 시켜보면 10-20% 정도는 dead ReLU에 빠져있지만, 그럼에도 train 자체는 잘 되기 때문에 현재까지 ReLU가 상용화된 것으로 보인다.
ReLU 함수에 bias 값을 주면서 W initialization 시 dead ReLU를 기피하려는 방법 또한 존재한다.
하지만 효과가 미미한지 대부분은 zero-bias를 사용하는 추세라고 한다.
ReLU의 문제들을 해결하기 위해서 아래와 같은 개선책들이 소개되고 있다. (그럼에도 불구하고 아직 ReLU를 가장 많이 사용하는 것으로 보인다만...)
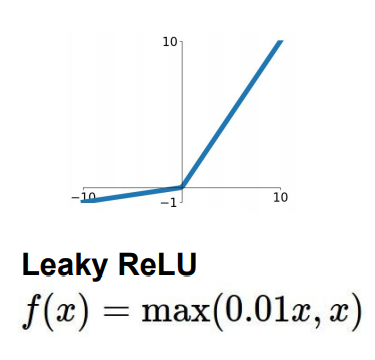
=> 음의 영역에서도 이제 saturation이 되지 않는 Leaky ReLU (dead ReLU 또한 존재하지 않는다)
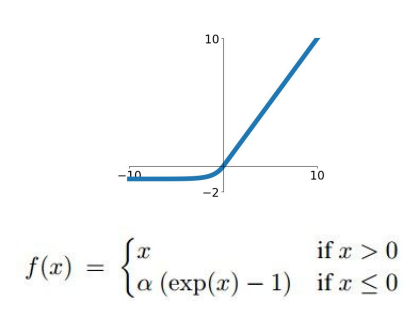
=> ELU(Exponential Linear Units) 함수도 존재한다. Saturation이 노이즈에 강해지긴 하지만, 여전히 vanishing gradient의 문제나 exp() 연산 포함 등의 한계도 존재한다.
위에서 언급된 ReLU, Leaky ReLU, ELU 등의 함수들은 각각의 장단점이 있기 때문에 때에 따라 다르게 사용하게 된다.
================ ================ ================ ================ ================
## Data Preprocessing (데이터 전처리)
일반적인 머신러닝에서는 전처리 과정은 아래와 같다.
data zero-centering(standardization(표준화)) -> normalization(정규화) -> 각각의 둘쑥날쑥한 피쳐들을 특정 범위 내로 전처리함
(아래 블로그 링크 참조)
가장 쉽게 배우는 머신러닝 2주차 : 전처리(Preprocessing)
머신러닝 기초
velog.io

그러나 이미지 데이터의 경우 딱히 normalization 과정(값의 범위를 0~1로 옮겨주는 과정)이 필요가 없다.
이미지 데이터는 픽셀이 모두 0~255로 같은 범위를 가지기 때문이다.
그렇기에 zero-centering 과정만 한다.
Zero-centering을 하는 이유는 학습 최적화를 위한 과정이다.
즉 input이 모두 양수이면, W가 모두 음수 또는 양수가 되어서 업데이트가 일방향으로만 일어나기 때문에 비효율적이다.
그렇기 때문에 zero-mean(0-평균)을 전처리로 해준다.
다만 zero-mean을 통해서 위 input이 모두 양수일때의 문제를 완전히 해결하지는 못한다고 한다.
첫번째 layer에서만 zero-centering이 되고, layer가 쌓일수록 activation function 값이 양수로만 나와서 이후에는 의미가 없다고 함.
Convolutional layer에서 오리지널 이미지 데이터를 필터 등으로 공간적인 구조로 바라봐야 하기에 이미지 데이터에서는 별다른 전처리 과정을 하지 않고 Zero-mean 과정만 거치는 것이 일반적이라고 한다.
================ ================ ================ ================ ================
## Weight Initialization

=> 만약 W가 모두 0이라면 어떻게 될까?
-> 모든 neuron이 같은 일을 하고 같은 값으로 업데이트가 된다. 즉 activation function이 사실상 없는 것이나 마찬가지이니 layer의 의미가 사라지게 된다.
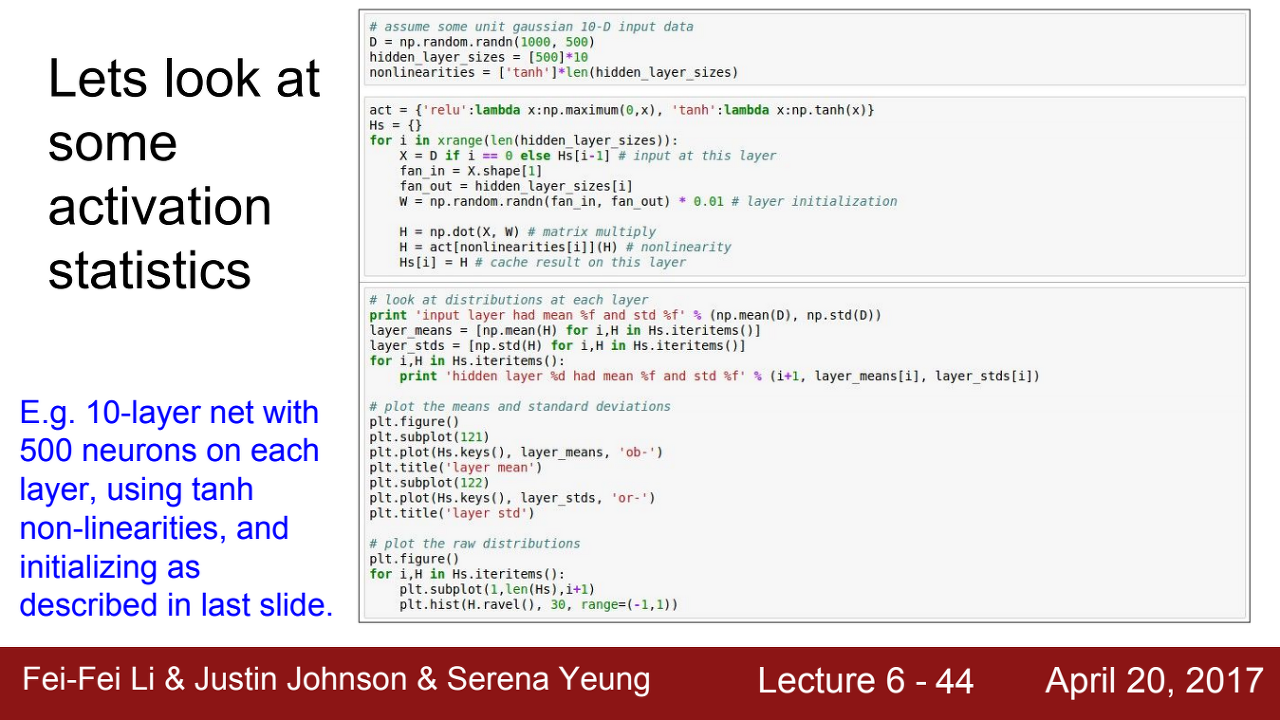
tanh 활성화 함수를 사용하고, 10-layer를 가지고 있으며 500개의 뉴런이 각 층에 있는 모델에서 W를 초기 설정하려고 예시를 생각해보자
만약에 임의의 작은 랜덤 값으로 W를 설정한다면?

=> 위 그래프처럼 출력값이 점점 0에 가까워지는 문제점이 생김.
이유는? 1보다 작은 W의 값들은 layer가 중첩됨에 따라 계속해서 곱해지니까 0으로 수렴해진다.
그렇다면 좀 더 큰 값으로 W를 초기화한다면? (즉 0에 수렴하지 않게 1이상의 값을 준다면?)
=> tanh은 x가 1과 -1인 지점은 saturated 지점이다. 따라서 saturation이 일어나서 gradient가 0이 될 확률이 존재한다.
이번엔 Xavier initilization을 소개한다.

Xavier 방식은 랜덤의 가우시안 분포 값에서 np.sqrt(fan_in)으로 나누어주어 스케일링의 방식을 해주는 것이다.
즉 입력값의 개수에 따라 상대적으로 값을 조정하여 initialization하기 때문에 합리적인 방식이다.
하지만 위 Xavier에 경우에서 tanh이 아닌 ReLU를 사용할 경우?
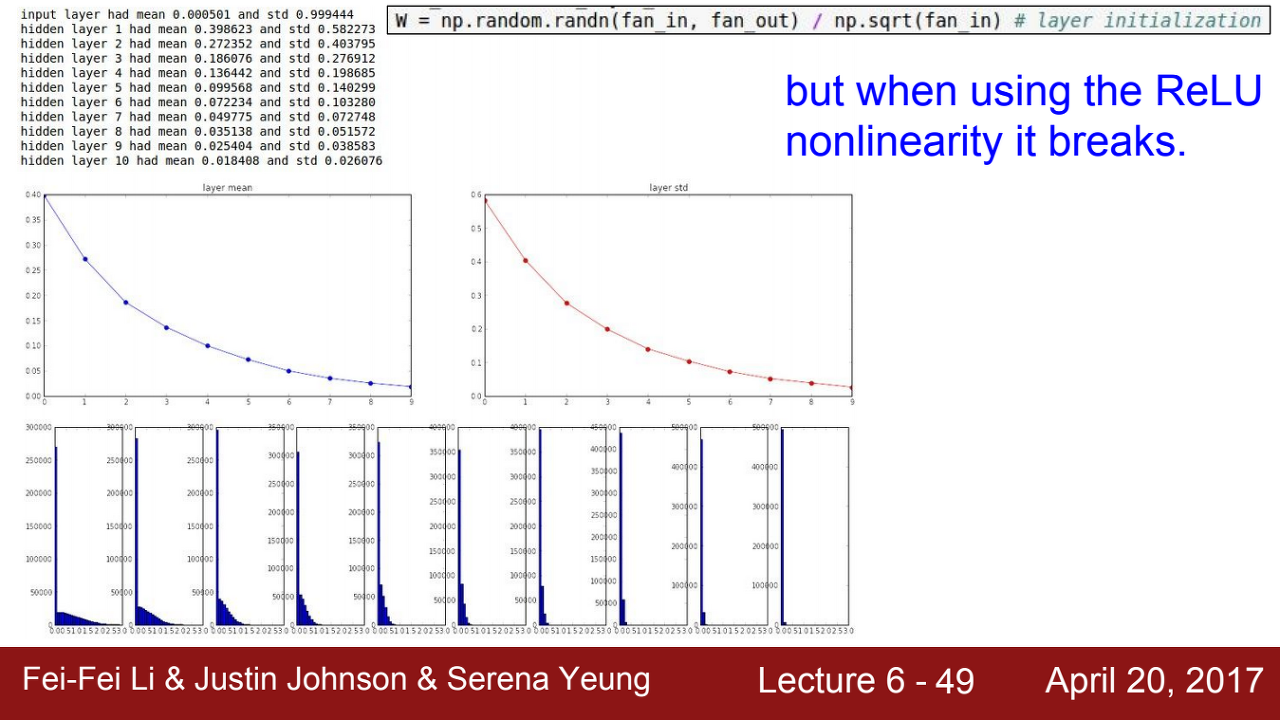
=> Zero-mean 함수였던 tanh과는 다르게 ReLU는 음수 부분이 모두 0이 된다.
따라서 활성화 함수를 지나면서 점점 std가 0에 가까워지고, 출력값들에 0이 많다면 W의 업데이트는 잘 이루어지지 않을 것이다.

=> 이러한 경우 강의에서는 뉴런의 절반 정도가 음수의 값으로 죽어나간다는 근거로, np.sqrt(fan_in)에 2를 더 나누어주었다.
따라서 위 오른쪽 그래프를 보면 마지막 layer에도 출력 값이 유의미한 값으로 살아있다는 것을 확인할 수 있다.
================ ================ ================ ================ ================
## Batch Normalization (배치 정규화)
앞서 Gradient의 변화량이 매우 작아지거나 커진다면 신경망을 효과적으로 학습시키지 못하고 Error rate가 낮아지지 않고 수렴해버리는 문제가 발생한다고 했다.
이러한 문제점을 해결하기 위해 자주 쓰이는 것이 ReLU라고도 했다.
이 모든 것들은 학습하는 과정 자체를 전체적으로 안정화하여 학습 속도를 가속시킬 수 있는 근본적인 방법을 'Batch Normalization(배치 정규화)' 라고 한다.
기본적으로 Normalization(정규화)는 학습을 더 빨리 하기 위해서, 또는 local optimum 문제에 빠지는 가능성을 줄이기 위해서 사용된다.
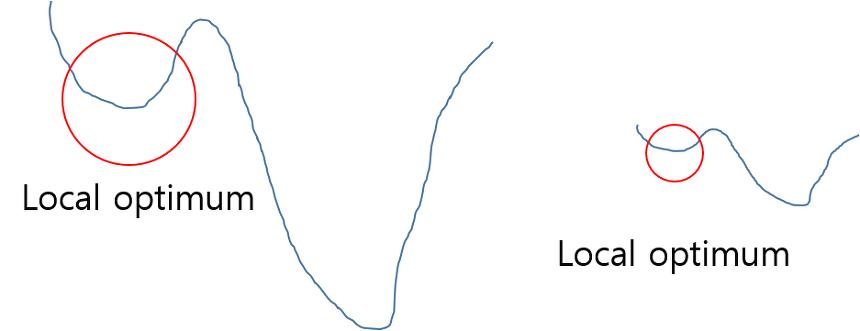
위 그림처럼 최저점을 찾을 때 Global optimum 지점을 찾지 못하고 local optimum에 머물러 있게 되는 현상이 발생하게 된다. 이에 normalization 과정을 통해 그래프를 왼쪽에서 오른쪽으로 만들어서 local optimum에 빠질 가능성을 낮추게 된다.
딥러닝에서 학습에서 불안정화가 일어나는 이유는 네트워크긔 각 레이어나 activation 마다 입력값이 분산이 달라지는 현상이 일어나기 때문이라는 주장이 있다.
따라서 이러한 현상을 막기 위해 각 레이어의 입력의 분산을 평균 0, 표준편차 1인 입력값으로 정규화시키는 방법이 있으며, 이를 Whitening(백색 잡음) 이라고 한다. 하지만 whitening만 존재한다면 backpropagation과 무관하게 진행되기 때문에 특정 파라미터가 계속 커지는 상태로 whitening이 진행될 수 있다.
위와 같은 whitening의 문제점을 해결하는 것이 Batch Normalization(배치 정규화) 이다.
Whitening과는 다르게 평균과 분산을 조정하는 과정이 신경망 안에 포함되어, 학습 시 평균과 분산을 조정하는 과정이 같이 조절되게 된다. (그 외 자세한 얘기는 아래 블로그 참조)
https://eehoeskrap.tistory.com/430
[Deep Learning] Batch Normalization (배치 정규화)
사람은 역시 기본에 충실해야 하므로 ... 딥러닝의 기본중 기본인 배치 정규화(Batch Normalization)에 대해서 정리하고자 한다. 배치 정규화 (Batch Normalization) 란? 배치 정규화는 2015년 arXiv에 발표된 후
eehoeskrap.tistory.com
따라서 각 뉴런마다 평균과 분산을 구하는 function을 통해 batch마다 normalization을 해주기 때문에 back propagation도 문제 없이 시행할 수 있다.
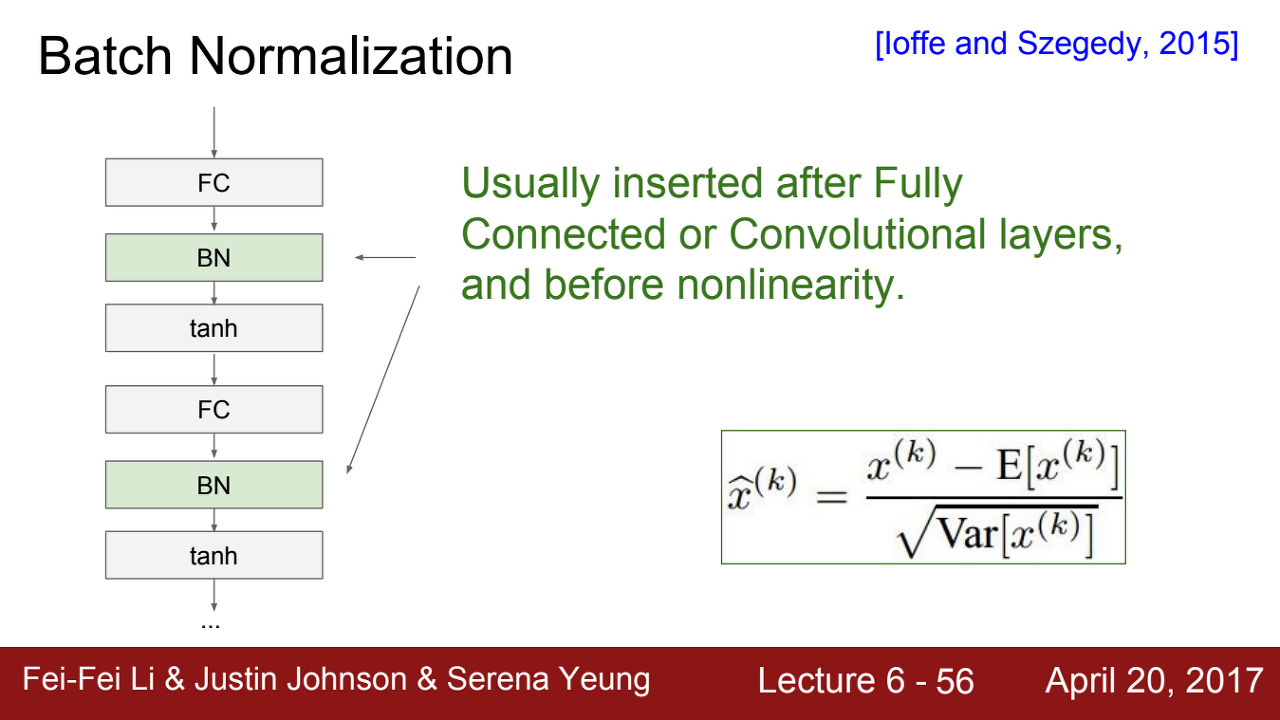
=> 이와 같이 ConV와 FC 층 이후, Activation function 이전에 Batch Normalization을 넣어주게 된다.
각 층에서 가중치 W이 곱해져서 layer를 지날 때마다 범위가 달라지기에 층마다 해당 배치 정규화를 넣어서 normalization을 진행하는 것이다.
배치 정규화를 거치게 되면 기울기의 흐름에 좋은 영향이 가서 robust한 결과를 도출할 수 있게 된다.
또한 learning rate의 범위를 확장시키고, initialization의 의존성을 줄여서 더 많은 initialization을 유도하는 효과도 존재하기에 Batch Normalization은 매우 중요하다.
마지막으로 input값 x의 영향들을 normalize하여 평균, 분산에도 영향이 가기에 regularization 효과도 있다.
================ ================ ================ ================ ================
## Babysitting the Learning Process
1. 데이터 전처리 (Data Preprocessing)
2. Architecture 선택 및 네트워크 초기화
3. Loss function 지정 및 regularization 고려
=> 초기 loss 체크
4. 일부의 데이터만 학습 (sanity check)
=> regularization은 이때 사용하지 않음
=> epoch마다 loss가 감소하는지 확인. 또한 train accuracy가 증가하는지 확인.
5. Learning rate 설정
=> 전체 데이터를 학습시키고 loss를 확인하면서 learning rate를 조정.
=> learning rate가 작으면 gradient 업데이트가 충분히 일어나지 않아서 loss가 잘 안 줄어듬
=> 반대로 너무 크면 NaNs cost 발산
=> learning rate는 보통 e-3 (0.001) ~ e-5 (0.00001) 사이를 사용한다
위와 같은 Babysitting the Learning Process 과정을 거치면 학습 성능 향상 및 시간 단축, 그리고 안정성 확보 등의 효과를 가질 수 있다.
================ ================ ================ ================ ================
## Hyperparameter Optimization
우선 Cross -validation 으로 training set을 학습시키고 validation set으로 평가하는 방식이다.
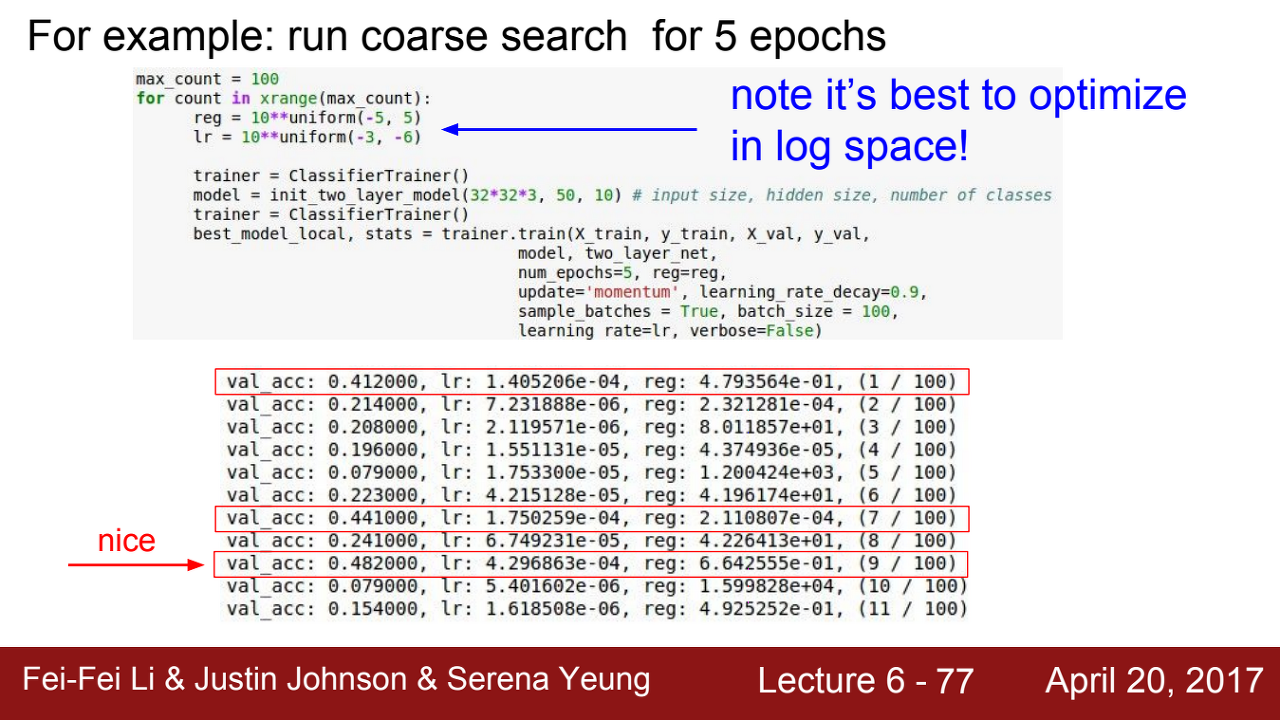
다음은 lr (learning rate)과 reg(regularization)을 최적화하는 예시.
lr의 경우 graident와 곱해지는 값이라서 아주 미세하게 log 값 범위로 조절해야 한다.
위 사진의 경우 빨간색 박스가 accuray가 높게 나온 상황인데, 이때의 lr은 e-04, reg 값은 e-04~01 값이라고 유추할 수 있다.

=> 위의 lr과 reg 값을 토대로 범위를 설정하니 accuracy가 올라갔으나, 아직 더 높게 올라갈 수 있다.
예를 들어 lr이 e-3 ~ e-4의 값을 가진다고 지정해버리면, e-0.28 과 같은 값은 놓칠 수 있기 때문에 더 높게 accuracy가 올라갈 기회를 놓쳤다고 볼 수 있다.

=> Grid search와 Random search 방식도 존재한다.
이 방법들은 hyperparameter 값들을 조합을 고정시켜서 좋은 조합을 뽑는 방식이다.
하지만 grid search의 경우 일정한 간격으로 조합을 찾기 때문에, 변수들 사이에서의 중요도를 무시한 채 계속해서 search를 한다는 점에서 Random search 방식이 더 낫다. (즉 더 중요한 variable에서 다양한 값들을 샘플링 할 수 있다)

위 그래프는 loss 그래프를 해석하는 방식에 대한 설명이다.
좋은 learning rate 값을 지니면 빨간색처럼 그려지게 된다.
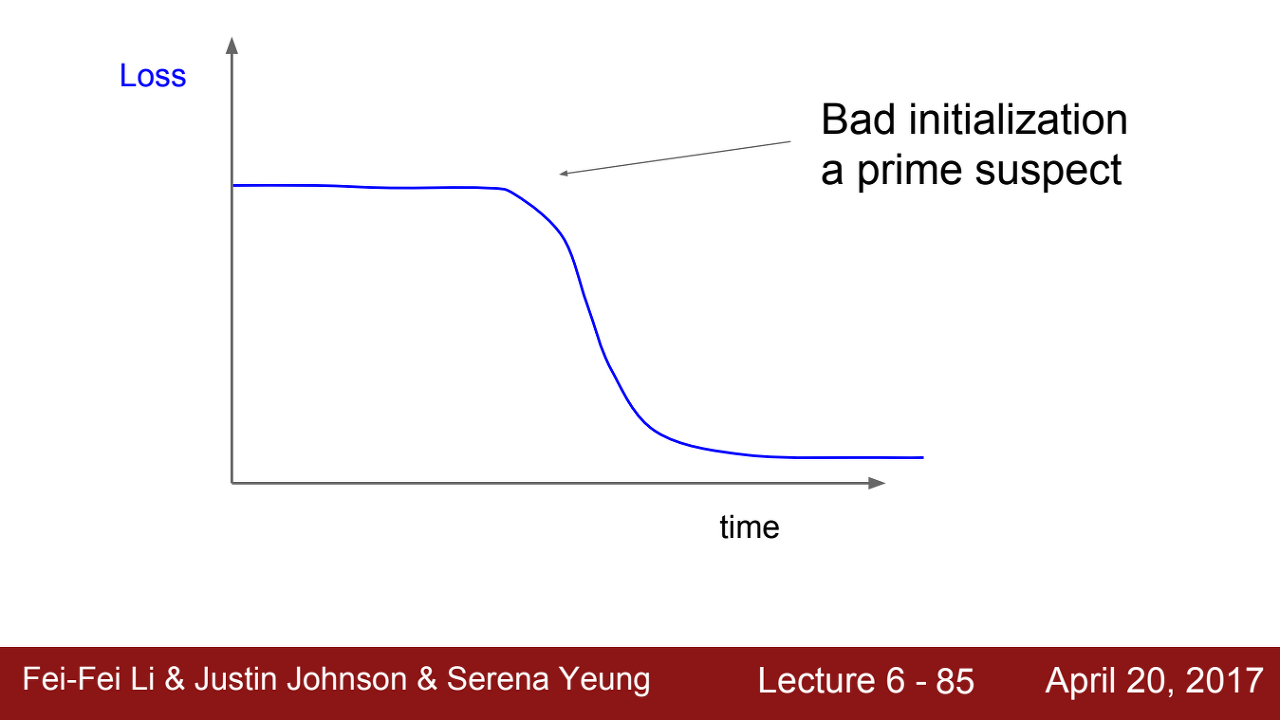
=> 만약에 위와 같이 평평하다가 갑자기 가파르게 내려가는 loss curve가 생긴다면 무엇이 문제일까
이는 초기의 initialization을 제대로 설정하지 못하여 gradient의 업데이트가 제대로 일어나지 않아서 생겨난 문제이다.
즉 gradient의 역전파가 초기에는 잘 진행되지 않다가 학습이 진행되면서 회복하는 형태이다.
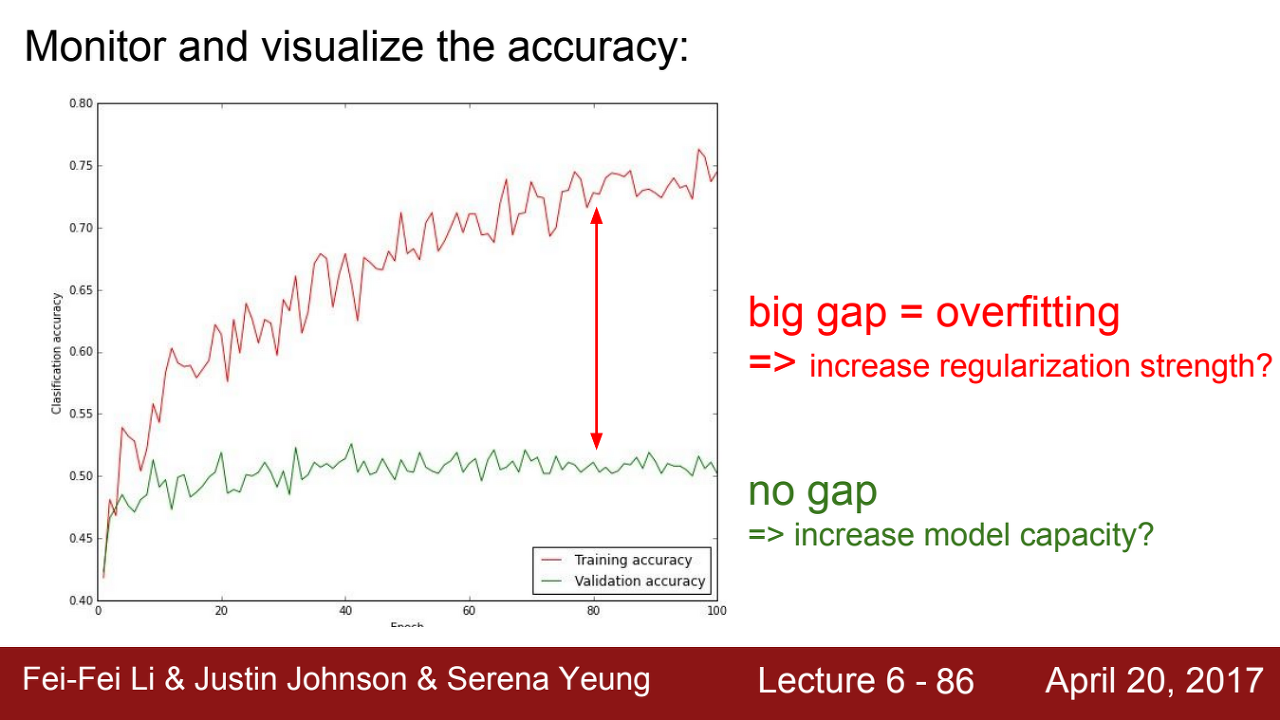
=> 또한 validation의 accuracy 값이 training 값과 차이가 많이 나면, 이는 곧 train set에 대한 overfitting(과적합)이 일어났다고 계산할 수 있다. 이러한 경우에는 regularzation을 높여주는 방식 등을 고려할 수 있다.
'Nvidia > CS231n' 카테고리의 다른 글
| cs231n 8강 (3) | 2024.01.18 |
|---|---|
| CS231n 7강 (2) | 2024.01.05 |
| CS231n 5강 (1) | 2023.12.15 |
| CS231n 4강 (0) | 2023.12.11 |
| CS231n 3강 (0) | 2023.12.07 |