
https://www.youtube.com/watch?v=h7iBpEHGVNc&list=PLC1qU-LWwrF64f4QKQT-Vg5Wr4qEE1Zxk&index=3
## Loss Function (손실함수)
앞서 2강에서 f(x,W) 에 대한 내용을 이어서 한다.
해당 함수에서 W는 곧 가중치 파라미터이다. 즉 f는 W에 의해 parameterized 되었다.
따라서 데이터 (x,y) 에 대한 제어는 없지만 가중치 W는 제어할 수 있으며, 예측된 class의 점수가 ground-truth 이미지와 일치하도록 만들어준다.
* ground-truth? => https://eair.tistory.com/16
[용어정리]Ground-truth
Ground-truth는 기상학에서 유래된 용어로 어느한 장소에서 수집된 정보를 의미합니다. Ground-truth는 보통 '지상 실측 정보'로 해석되며 인공위성과 같이 지구에서 멀리 떨어져서 지구를 관찰하였을
eair.tistory.com

=> 위 예시에서는 고양이 사진임에도 Dog score가 가장 높았기에 W가 좋지 않다라고 볼 수 있다. 하지만 위와 같은 결과를 loss function을 이용하여 다룰 수 있다.
Loss function(손실 함수) 란 모델이 나타내는 확률 분포와, 데이터가 따르는 실제 확률 분포 사이의 차이를 나타내는 함수가 정의다.
즉 W가 얼마나 좋은지 실제값과 예측값의 차이를 수치화하여 정량화하는 것이며, loss function 값을 최대한 줄이는 것이 f(x,W)=Wx + b 에서 좋은 W,b 값을 찾아나가는 것이다
위와 같은 과정을 optimization(최적화 과정) 이라고 한다.

위에서의 최종 loss를 계산하려면 dataset에서 각 N개의 샘플들의 Loss 평균을 구하면 된다.
이와 같이 image classification에서 loss function을 구하기 아주 적합한 방법 중 아래 Multiclass SVM loss 가 있다.
* Multiclass SVM Loss


위 식에서 Sj는 오답 카테고리의 스코어고, Syi는 정답 카테고리의 스코어이다. 그래프를 그려보면 Hinge같이 생겨서 Hinge loss라고도 한다.

위 사진을 예시로 hinge loss 값을 구해보면
고양이를 예시로
Syi = 3.2
Sj = 5.1(car) , -1.7(frog)
car가 Sj일때는 3.2 > 5.1 + 1이 성립하지 않아서
Sj - Syi + 1 = 5.1 -3.2 + 1 => loss 값은 2.9
frog가 Sj 일때는 3.2 > -1.7 + 1 이 성립되기에 loss 값이 0
즉 첫번째 Cat에 대한 데이터 Loss 값은 2.9 + 0 = 2.9가 된다.
모든 데이터를 위와 같이 계산한다면 최종 Loss는
(2.9 + 0 + 12.9) / 3 즉 5.27의 값을 가지게 된다.
5.27은 W에 대한 정량적 평가가 되게 된다.
다만 multi-class SVM loss는 데이터에 민감하지 않다는 특성이 있다.
만약 자동차의 score가 4.9가 아니고 3.9여도 여전히 자동차의 loss 값은 0이 유지된다.
따라서 score가 몇 점인지에 대한 평가보다는, 정답 클래스가 정답이 아닌 클래스보다 높은지에 대한 평가만이 가능하다.

=> SVM loss를 numpy로 짠 python 코드
+ Squared hinge loss란 해당 (Sj - Syi + 1)의 제곱승이다.
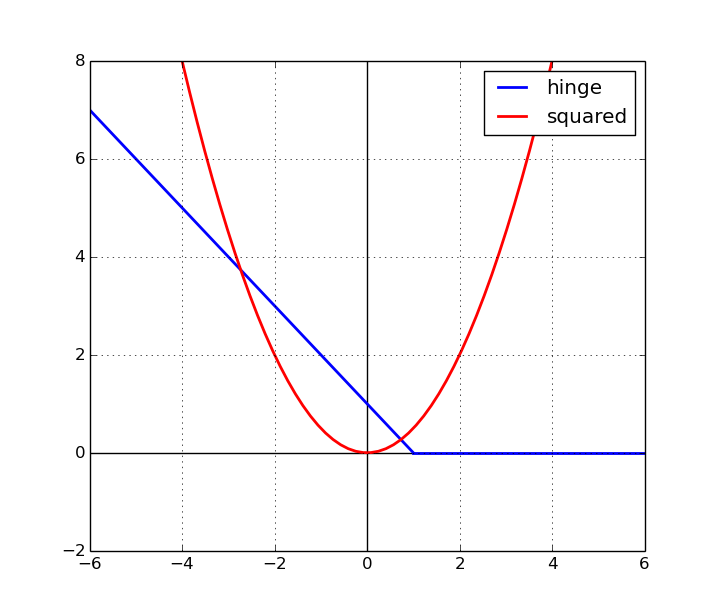
=> 위와 같이 그래프가 제곱승으로 곡선으로 가파르게 올라가기 때문에, '매우' 좋다, 안좋다를 따질 때 더 유용하게 적용할 수도 있다. 하지만 보통은 일반 SVM loss를 사용한다.
>> Loss Function의 선택에 따라서 자신이 확인하고 싶은 특정 에러를 확인하거나, 어떤 에러가 트레이드오프 되는지 등을 설정할 수 있다. 따라서 Loss Function의 설계가 매우 중요하다.
=========== =========== =========== =========== =========== =========== =========== ===========
## Regularization Loss
위의 SVM loss에서의 한계점이 있다.
해당 한계점은 다음과 같은 질문에서 시작된다
과연 우리가 구하려 하는 W 값이 유일한 값을 가질까?
결론은 아니다. 2W, 3W, ... 등도 모두 다 같이 loss가 0이 나오게 된다. 즉 W 값은 여러개이다.
이러한 부분이 왜 문제가 되냐면, 만약 train set에 맞춰서 W을 잘 설정한다고 해도, 해당 값이 unique하기 않기 때문에 test set에서도 해당 W가 잘 들어맞을 거라는 보장을 할 수가 없다.
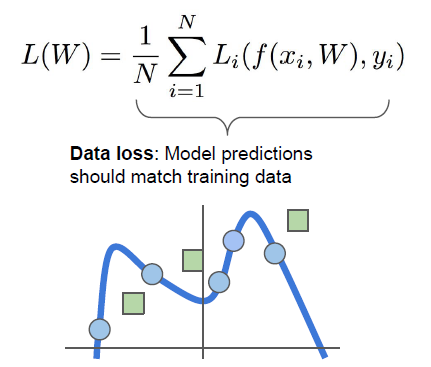
=> 이러한 그래프와 같이 train set에 대해서 파란색 선으로 값들을 구했다고 쳐도, 우리가 고려하려는 것은 test set이다. 만약 test set에서 초록색 값들이 나타난다면 이를 예측하지 못하기에 정확도가 떨어진다. 이러한 문제점을 Overfitting(과적합) 이라고 한다.

=> 그렇기 때문에 train set한테 완벽하게 fit 한 파란색 그래프만을 가지기보다는, 초록색 선처럼 그래프가 형성되는 것이 더 이상적이다. 따라서 regularization(규제) 가 필요하다.
| L(W)=N1∑i=1NLi(f(xi, W), yi)+λR(W) |
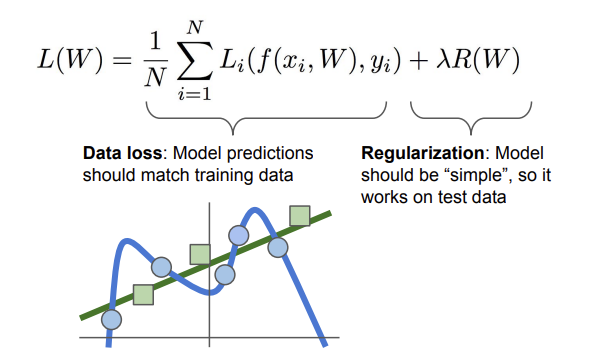
λ 는 hyperparameter이며 R(W)와 trade-off 관계를 가지게 된다.
R(W)는 Regularization 부분으로 해당 모델이 너무 train set data에만 fit 하지 않게 W를 조정하는 역할을 한다.
즉 모델이 너무 복잡해지는 것을 방지하기 위해서 soft penalty인 regularization을 추가하는 거라고 볼 수 있다.
Regularization에는 다음과 같은 많은 종류가 있다.

이 중 어떠한 것을 선택할지에 대해서는 다음과 같은 부분들을 고민해볼 수 있다.

만약 위 W1과 W2가 주어졌을때, Linear Classification (f=xW)으로 보면 두 개의 W는 같은 스코어를 가지기에 data loss 값 또한 동일하다. 이러한 상황에서

=> L2의 경우에는 W2의 데이터를 더 선호하게 된다. 즉 W를 최대한 spread out을 해서 모든 input 요소들을 골고루 고려하기를 원하게 된다. (Ridge Regression)
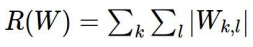
=> 이에 반해 L1 은 W1의 데이터를 더 선호하게 된다. 0이 많으면 이를 좋다고 판단하게 된다. (Lasso Regression)
따라서 모델과 데이터 특성에 따라서 Regularization Loss를 잘 설계하는 것이 필요하다.
* Softmax classifier (Multinomial Logistic Regression)

=> 이해한 바로는 해당 Softmax function은 score를 모두 이용하며, 이 score에 지수를 취하여 양수가 되게 한다. 그리고 지수들의 합으로 정규화를 시킨다. 해당 확률은 0~1의 값을 가진다.
Softmax의 방식의 경우 score 자체에 추가적인 의미를 부여한다. 이는 정답과 비정답 클래스를 비교하는 방식인 SVM loss 방식과 차이를 보인다.
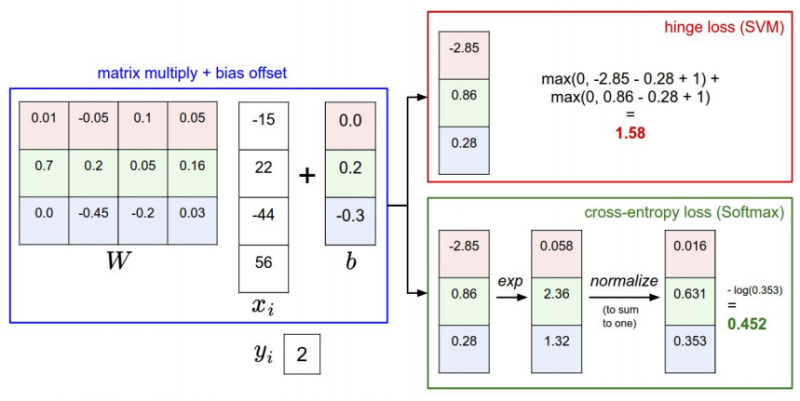
=> SVM은 1의 margin 값을 가지기 때문에 correct score가 조금씩 변경되더라도 loss 값의 차이는 크지 않다. 이에 반해 softmax는 score 하나하나마다 정답으로 가려고 하기 때문에 SVM보다 더 민감하다는 차이점을 가진다.
=========== =========== =========== =========== =========== =========== =========== ===========
## Optimization
지금까지 배운 내용을 토대로 말하자면 우리의 최종 목적지는 최종 손실함수가 최소가 되게 하는 W와 b의 값을 구하는 것이다.
f(x,W) = xW + b 에서의 weight와 bias 값을 찾아나가는 과정, 이를 optimization(최적화)라고 한다.
이러한 최적화 방법을 고안해내는데 다음과 같은 고민들을 해볼 수 있다.
1. Random search
=> 즉 W 값을 계속해서 랜덤으로 찾아나아가는 방법. 정답률이 매우 적기 때문에 사용하지 말아야 한다.
2. Gradient
* numerical gradient
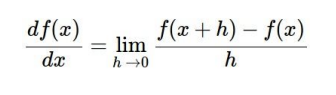
=> 단순하게 모든 loss 값을 직접 대입하고 계산하여 증감 파악하는 방법. 물론 이 방법 또한 너무나도 많은 시간과 돈을 소모하기 때문에 사용하지 말아야 하는 방법.
* analytic gradient

=> 미분을 통해 계산하는 방식이며, 정확하고 빠른 대신 오류가 발생하기 쉽다(error-prone)
그렇기에 gradient check 방식을 통해서 적절하게 잘 구현되는지 값을 체크할 수 있다.
* gradient descent
| while True: weights_grad = evaluate_gradient(loss_fun, data, weights) weights += - step_size * weights_grad # 파라미터 업데이트(parameter update) |
=> 우선 W 값을 임의의 값으로 초기화한다. 그러고 나서 loss와 gradient를 계산한 뒤 가중치를 gradient의 반대 방향으로 업데이트 한다. 그렇게 되면 언젠가는 수렴하게 된다..
하지만 이 방법 또한 데이터의 크기가 크면 클수록 비효율적인 방법이다. 따라서 아래 SGD라는 개선점이 나오게 되었다.
3. Stochastic gradient descent (SGD)
전체의 data set을 보고 gradient와 loss를 계산하는 것은 비효율적일 수 있다. 그렇기 때문에 Minibatch라는 작은 샘플 집합으로 나누어서 학습을 진행하게 된다.

=> Training data set이 수백만개가 주어질 수 있는데, 만약 위 gradient descent 방식을 사용하면 파라미터 한번 업데이트하려고 학습 training data 전체를 계산에 사용하게 되어 낭비가 될 수 있다.
그렇기에 SGD는 batches만을 이용하여 gradient를 구하게 되는 것이다.
'Nvidia > CS231n' 카테고리의 다른 글
| CS231n 7강 (2) | 2024.01.05 |
|---|---|
| CS231n 6강 (1) | 2023.12.19 |
| CS231n 5강 (1) | 2023.12.15 |
| CS231n 4강 (0) | 2023.12.11 |
| CS231n 2강 (0) | 2023.12.05 |