
https://www.youtube.com/watch?v=d14TUNcbn1k&list=PLC1qU-LWwrF64f4QKQT-Vg5Wr4qEE1Zxk&index=4
## Backpropagation (오차역전파)
수학적인 부분은 요약할 수 있을 정도로 이해를 하지 못했다... (계속 공부해야 할듯)
https://evan-moon.github.io/2018/07/19/deep-learning-backpropagation/
[Deep Learning 시리즈] Backpropagation, 역전파 알아보기
이번 포스팅에서는 저번 포스팅에 이어 에 대해서 알아보려고 한다. 앞서 설명했듯, 이 알고리즘으로 인해 에서의 학습이 가능하다는 것이 알려져, 암흑기에 있던 학계가 다시 관심을 받게 되었
evan-moon.github.io
=> 다만 이 블로그 링크를 통해 해당 개념에 대해서 공부를 진행했다..
* 이해한 만큼 정리해보자면
=>Chain Rule : 미분의 연쇄법칙.
합성함수의 개념을 먼저 보자면, 가령 이런 것.
F = f(g) = g * 3 이고 , g(x) = x+1 일 때, 최종 f(g(x)) 에서 g(x) 함수에 제공하는 x 값이 변경되면 최종적으로 F 변수에게도 영향이 간다.
Chain Rule은 위와 같은 합성함수의 미분이라고 보면 된다.
Chain Rule 이란 각각 함수 f와 g의 인자 값들이 변경된다면 최종 변수 F 에게 얼마나 변화량에 기여하는지 기여도를 확인하는 것이다.
그리고 이렇게 단순한 인자가 하나뿐인 함수 외에, 그 이상의 관련도도 계산할 수 있다.
즉, 그 전 단계의 gradient 값을 결과 값의 gradient와 변수 사이의 관계를 이용하여 구할 수 있다.
그렇기에 Chain Rule을 통해 인접한 노드 간의 정보를 알고 있고, 결과 값의 gradient를 알고 있으면 이전 노드의 gradient를 구할 수 있게 되는 것이다.
=> Forward-propagation
특정 Activation Function과 Error Function을 사용하는 모델이 있다고 가정하자.

만약 마지막 output 값인 y1과 y2 에 특정 값들이 산출되기를 원하며, input 값인 x1과 x2의 값은 특정 값들이 설정된다고 해보자.
마지막으로 W 값은 임의대로 설정이 됐다고 설정한다.
Forward-propagation은 위의 특정 Activation Function과 Error Function 을 통해서 실제 x1, x2, W 값을 통해 어떠한 output y1, y2 값이 나오는지에 대한 계산이다.
그리고 높은 확률로 위 Forward-propagation을 거치면 초기에 희망했던 y1, y2 의 값을 얻을 확률은 극히 작다.
=> Backpropagation
그렇기 때문에 Backpropagation을 사용하게 된다. 해당 부분에 대해서 완벽하게 산출 과정을 이해하지는 못했지만, 지속적으로 Backpropagation 과정을 거치며 테스팅을 하면 결국 초기에 원했던 y1, y2 값에 점점 수렴해가는 것을 확인할 수 있다.
* 수학이 약한 관계로 이번 강의는 이해하기가 어렵다...
https://velog.io/@cha-suyeon/CS231n-4%EA%B0%95-%EC%A0%95%EB%A6%AC-Introduction-to-Neural-Networks
cs231n 4강 정리 - Introduction to Neural Networks
이번 포스팅은 standford university의 cs231 lecture 4를 공부하고, 강의와 슬라이드를 바탕으로 정리한 글임을 밝힙니다.제가 직접 필기한 이미지 자료는 별도의 허락 없이 복사해서 다른 곳에 게시하는
velog.io
이해하지 못한 부분을 억지로 요약하는것보단, 잘 쓰여진 블로그 링크를 참조하는 것이 나을것 같기에, 이정도로 마무리 하려고 한다...
결론은 backpropagation을 통해서 적정 W 값을 찾아나아갈 수 있다, 이게 핵심이지 않나 싶다.
=========== =========== =========== =========== =========== =========== =========== ===========
## Neural networks
지금까지는 linear function, 즉 f = Wx + b 같은 간단한 함수에 대한 학습을 진행했다.
하지만 현실의 AI 모델을 세우기 위해서는 더 복잡한 문제를 해결할 방법을 찾아야 한다.
위와 같은 복잡한 문제를 해결하기 위해서 사람들은 신경망 구조에서 아이디어를 얻어서 모델을 만든다.
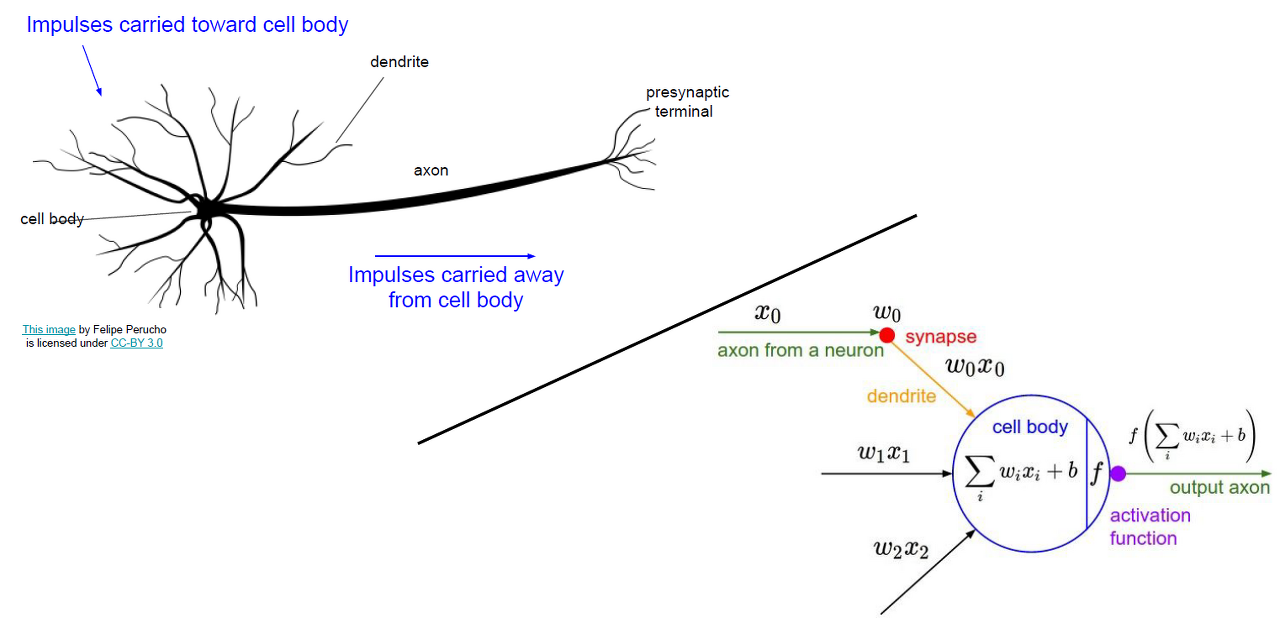
신경망이 중첩되어 복합적인 연쇄반응을 일으키는 것처럼, Linear function을 겹겹이 쌓아간다면 더 복잡한 문제를 해결할 수 있는 모델을 가진다는 아이디어다.
(완벽하게 뇌의 신경망 구조와 1:1로 일치하는 구조가 아님은 주의하라고 한다(것보단 아이디어를 가져온 느낌인듯))
예를 들어 f = Wx 라는 간단한 linear function이 있더라도, f = W3 * max(0, W2 * max(0, W1*x)) 와 같이 3-layer network와 그 이상도 생각해볼 수 있다. 위에서 배운 backpropagation으로 각 gradient들을 계산할 수 있다.
* Activation Function (활성화 함수)
Activation function에 대해서는 후반부에 더 자세히 다룬다고 한다.

많이 사용되는 활성화함수는 ReLU와 Sigmoid 등이 있다는 것 정도만 우선 알면 될 것 같다.
위와 같은 Activation function은 매 function이 중첩되어 결국 복잡한 모델을 구현하는데 사용이 된다.
* Neural networks architecture

왼쪽의 경우 layer가 3개임에도 불구하고 2-layer Neural Net이라고 부른다.
왜냐하면 W 즉 weight를 가지고 있는 것만 layer로 치기 때문이다.
초기에 투입되는 input layer같은 경우 W가 없기 때문에 계산에서 제외된다.
그리고 왼쪽, 오른쪽 모형 모두 모든 노드들이 연결되어 있는 것을 확인할 수 있다.
위와 같은 구조를 Fully-connected layer, FC layer라고 부른다.
layer로 구성하면 효율적인 계산을 할 수 있다.
하나의 layer에서 하나의 연산을 진행하기 때문에 아무래도 연산하는데 편의성이 제공된다고 한다.
'Nvidia > CS231n' 카테고리의 다른 글
| CS231n 7강 (2) | 2024.01.05 |
|---|---|
| CS231n 6강 (1) | 2023.12.19 |
| CS231n 5강 (1) | 2023.12.15 |
| CS231n 3강 (0) | 2023.12.07 |
| CS231n 2강 (0) | 2023.12.05 |