
https://www.youtube.com/watch?v=_JB0AO7QxSA&list=PLC1qU-LWwrF64f4QKQT-Vg5Wr4qEE1Zxk&index=7
이번 강의는 사실 영상 강의는 시청하지 않고 아래 블로그들을 참조해서 정리했다... (강의가 이해되지 않음...)
https://velog.io/@cha-suyeon/cs231n-7%EA%B0%95-%EC%A0%95%EB%A6%AC-Training-Neural-Networks-II
cs231n 7강 정리 - Training Neural Networks II
이번 포스팅은 standford university의 cs231 lecture 7을 공부하고, 강의와 슬라이드를 바탕으로 정리한 글임을 밝힙니다. Reference 💻 유튜브 강의: Lecture 7 | Training Neural Networks Ⅱ 💻 한글
velog.io
https://inhovation97.tistory.com/24
cs231n 7강 Training Neural Networks, Part 2 정리
7강 Neural NetworksTraining Neural Networks, Part 2를 포스팅하겠습니다. 내용이 점점 깊어질수록 어려워지네요. 지난 강의에서 많은 것들을 배웠습니다. 이번 강의는 지난강의의 연장선인 part 2부분입니다
inhovation97.tistory.com
## Optimization 알고리즘 소개

=> optimization이라는 것은 결국 빨간 지점 (최소의 loss 값을 가지는 w) 를 찾는 것이 목표이다.

1. Gradient Descent (θ=θ−α∗∇J(θ))
=> 가장 기본적인 최적화 알고리즘. 1차 도함수에 의존하는 알고리즘이며, 쉽게 이해하고 계산할 수 있다는 장점이 잇으나 계산하기 위해서 큰 memory를 필요로 하게 된다.
2. SGD (Stochastic Gradient Descent) (θ=θ−α⋅∇J(θ;x(i);y(i)))
=> Gradient Descent의 변형. 하지만 여전히 global minima를 달성한 이후에도 계속해서 shooting이 일어날 수 있다.
위 문장의 의미는 다음과 같다.

=> 최저점이 아님에도 불구하고 극대값들 사이에의 극소값(기울기가 0이 되는 지점)에 안착하게 되는 현상을 local minima라고 한다. 반대로 global minima는 전체 그래프의 최극소값.
3. Mini-Batch Gradient Descent (θ=θ−α⋅∇J(θ;B(i)))
=> Gradient Descent 류의 변형된 알고리즘 중에서는 가장 좋은 결과값을 가진다고 한다. Data Set을 다양한 배치로 나누며, 매 배치 후에 parameter가 업데이트 되는 형태이다. 하지만 역시 Gradient Descent류 알고리즘들은 local minima에 안착하게 될 수도 있다는 단점을 가진다.
4. Momentum (V(t)=γ∗V(t−1)+α∗∇J(θ))
=> SGD의 높은 분산을 줄이고 수렴을 더 부드럽게 하기 위해서 만들어짐. 하지만 수동으로 정확하게 선택해야하는 hyper parameter ( γ )가 하나 더 늘었다는 한계점을 가진다.
5. NAG(Nesterov Accelerated Gradient) (V(t)=γV(t−1)+α∗∇J(θ−γV(t−1)))
=> Momentum이 너무 높으면 알고리즘이 local minima를 놓치고 계속 상승하는 현상을 고치기 위해 NAG가 만들어졌다. 이에 따라 gloabl minima를 놓치지 않으며 local minima를 만나면 느려지는 장점을 가진다. 하지만 여전히 hyper parameter는 수동으로 선택해야 하는 한계점을 가진다.
6. Adagrad
=> 위에서 언급된 모든 optimizer의 단점 중 하나는 learning rate가 모든 parameter와 각 주기에 따라 일정하다는 것이다. 따라서 Adagrad는 learning rate를 변경하는 것을 고려했다.
=> 일반적으로 non-convex보다 convex 상황에서 Adagrad의 효과가 더 좋다고 한다.
=> 이 방법 또한 문제점이 있는데, stepsize가 오랜 시간동안 지속된다면 grad가 매우 작아져서 속도가 굉장히 느려지게 된다.
7. AdaDelta
=> 위의 Adagrad에서 학습이 안되는 문제를 해결하기 위해 특정 hyper parameter가 추가된 형태.
8. Adam
=> 사실상 현재까지 가장 좋은 방식의 알고리즘. Adagrad와 momentum의 장점을 같이 사용하는 형식인 것으로 보인다.
=> Adam은 1차, 2차 모멘텀으로 작동한다. Global minima를 찾다가 최솟값을 뛰어넘을 수 있기 신중하게 속도를 약간 낮추어서 작동하게 된다.

=> 확실히 Adam이 최고의 성능을 낸다. 그래서 가장 좋은 기본 선택지로 사용된다.
======== ======== ======== ======== ======== ======== ======== ======== ======== ========
## Ensemble Models

=> 여러 모델들을 평균내서 이용하는 앙상블 모델은 엄청난 향상을 노린다기보다는 최종 성능에서 1~2% 성능을 끌어올리는데 많이 사용되게 된다.
=> 싱글 알고리즘은 주어진 data set에 대해 완벽한 예측을 못할 수도 있다. 그렇기 때문에 여러 모델을 만들고 결합하여 전체 정확도 향상을 노리는 것이다.
아래는 (https://velog.io/@cha-suyeon/cs231n-7%EA%B0%95-%EC%A0%95%EB%A6%AC-Training-Neural-Networks-II)애서 발췌한 앙상블 모델의 방법론에 대한 정리 글이다.
| 1) Same model, different initializations cross-validation을 사용해서 가장 좋은 hyper parameter를 결정한 다음, random initialization가 다른 여러 모델을 훈련합니다. 이 방식이 위험한 이유는 다양성이 initialization로 인한 것 뿐이라는 것입니다. 2) Top models discovered during cross-validation cross-validation을 사용해서 최적의 hyper parameter를 결정한 다음 상위 몇 개 모델(예를 들어, 10개)을 선택하여 ensemble을 구성합니다. 이는 ensemble의 다양성을 향상 시키지만 차선의 모델을 포함할 위험이 있습니다. 실제로 cross-validation 후에 모델을 추가로 retraining 할 필요가 없으므로 이 작업을 수행하는 것이 더 쉬울 수 있습니다. 3) Different checkpoints of a single model training이 매우 비용이 많이 드는 경우에, 일부 사람들은 시간이 지남에 따라 single network의 다른 checkpoints를 취해 (예를 들어, 매 epoch마다) ensemble을 형성하는데 제한적으로 성공했습니다. 이건 다양성이 부족하긴 하지만 여전히 training에서는 잘 작동합니다. 이 접근 방법의 장점은 비용이 적게 든다는 것입니다. 4) Running average of parameters during training 마지막 point와 관련하여 거의 항상 2%의 성능을 얻는 방법은 training 중에 이전 가중치의 기하급수적으로 감소되는 합계를 유지하는 네트워크 가중치를 메모리에 유지하는 방법입니다. 이렇게 하면 지난 몇 번의 반복에 대한 네트워크 상태를 평균화 할 수 있습니다. 지난 몇 단계에 거쳐 부드러워진 가중치는 거의 항상 더 나은 validation error를 달성합니다. |
======== ======== ======== ======== ======== ======== ======== ======== ======== ========
## Data Augmentation
=> Data Augmentation은 Overfitting의 문제를 해결하는 방법이다.

=> 위 사진에서 가장 왼쪽의 overfitting은 training data인 o에는 잘 맞지만 ㅁ 에는 잘 맞지 않게 된다.
이에 대한 근본적인 해결 방법은 training data를 늘리는 것이다. 하지만 다음과 같은 해결책들도 고려해볼 수 있다.
1. collect more
2. Synthesize
3. Augment
이중 3번인 Data Augmentation에 대해서 설명한다.
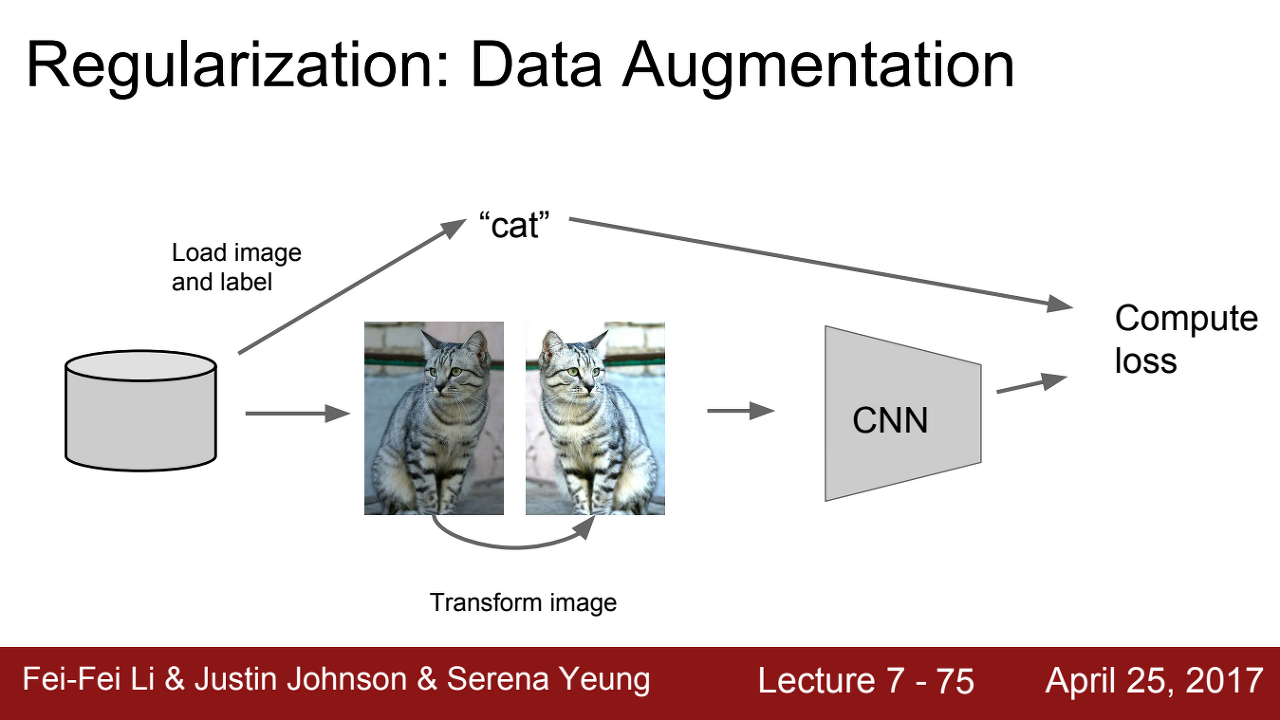
=> 이는 학습 중에 label은 보존한 상태에서 이미지만 변형시키면서 학습시키는 방법이다.
이미지를 변형시키는 방법으로는

=> horizontal flips

=> rancdom crops and scales

=> color jitter
외에

=> 이러한 것들이 있다.
======== ======== ======== ======== ======== ======== ======== ======== ======== ========
## Dropout regularization
=> Dropout은 심층 신경망에서 가장 인기 있는 regularization 방법 중 하나이다.
=> 매 training step에서 각 뉴런은 임시적으로 드롭아웃 될 확률 p를 가지게 된다.
그래서 p는 dropout rate라 부르며 hyper parameter이다.
이 p의 확률로 각각의 층에 대해 node를 삭제하게 된다. 이러면 더 간소화되고 작은 네트워크가 만들어져서 overfitting을 방지해주게 된다.
따라서 모델이 overfitting이면 dropout rate를 늘리고, 반대의 상황에는 rate를 내리게 된다.
======== ======== ======== ======== ======== ======== ======== ======== ======== ========
## Transfer Learning
=> data의 양은 한정적이고, 각각을 위해서 모델 생성 및 학습 비용이 많이 드는 현상은 비생산적이다.
=> 그렇기에 transfer learning (전이 학습)을 거쳐서 기존 data set을 최적으로 활용하게 된다.

=> imagenet을 가지고 우선 큰 data를 통해 학습을 시킨다.

=> 그리고 위에서 훈련시킨 모델을 작은 data set에 적용시킨다. 나머지 data들은 freeze시킨다.
=> 그리고 데이터 영에 따라 traind을 다시 시킬 layer를 약간 조정해주는 fine tuning을 고려해볼 수 있다.
이상적으로 transfer learning이 사용되면 최적화가 일어나서 시간을 절약하고 더 좋은 성능을 얻어낼 수도 있다.

=> transfer learning을 진행하면 위와 같이 4가지 경우의 수가 나온다.
이를 각각 해석하자면
- 이미 학습한 모델에 포함된 레이블이 많이 포함 돼있고, 그 데이터가 작다면, linear clssifier
- 이미 학습한 모델에 포함된 레이블이 많이 포함 돼있고, 그 데이터가 크면, fine tune
- 이미 학습한 모델에 포함된 레이블이 별로 없고, 그 데이터가 작다면, 노답
- 이미 학습한 모델에 포함된 레이블이 별로 없고, 그 데이터가 작다면, finetune을 크게 설정
'Nvidia > CS231n' 카테고리의 다른 글
| cs231n 8강 (3) | 2024.01.18 |
|---|---|
| CS231n 6강 (1) | 2023.12.19 |
| CS231n 5강 (1) | 2023.12.15 |
| CS231n 4강 (0) | 2023.12.11 |
| CS231n 3강 (0) | 2023.12.07 |