
https://www.youtube.com/watch?v=OoUX-nOEjG0&list=PLC1qU-LWwrF64f4QKQT-Vg5Wr4qEE1Zxk&index=2
### Image Classification
- 고양이 사진의 예시

위와 같은 고양이 사진을 봤을 때 컴퓨터는 해당 사진을 오른쪽과 같은 숫자의 집합으로 인식한다.
하지만 위의 방법에는 여러가지 문제가 있는데
자세가 달라지거나, 조명이 달라지거나, 배경과 사물의 식별이 용이하지 않거나, 고양이 종이 달라지거나 등등...
컴퓨터가 인식하는 숫자의 조합은 큰 차이가 생겨진다.
def classify_image(images):
# ...
return class_label
위와 같은 문제점들이 생기기 때문에 edges를 추출하는 방법도 나왔었다.
즉 눈,코,입,귀 등의 특징적인 부분들의 edges를 통해 비슷한 점이 있다면 이를 고양이로 인식하는 방법이다.
하지만 이 방법 또한 변화에 robust하지 않기 때문에 결과물이 별로이다.
=========== =========== =========== =========== =========== =========== =========== ===========
### Data Driven Approach
위와 같은 분류법이 효율적이지 않기에 생각되는 다른 접근 방식은 데이터 중심 접근방법이다.
즉 수많은 images, labels를 모은 후 training 하고 해당 모델을 평가하는 것이다.
def train(images, labels):
# machine learning !!
return model
def predict(model, test_images):
# ...
return test_labels
유사함 판단 정렬 기준에 대해서는 다음과 같은 비교 함수를 소개했다.
* L1 distance (Manhattan Distance)
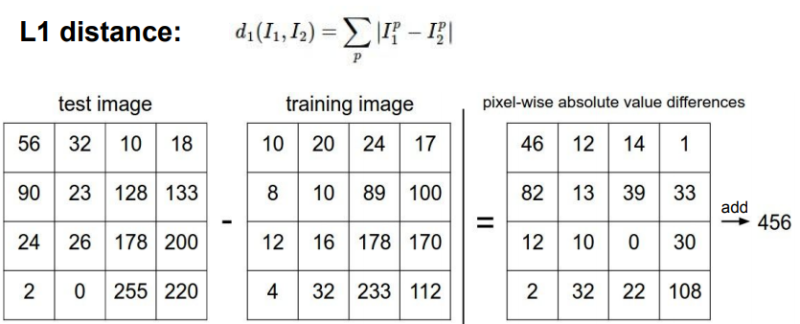
각 픽셀값의 차이의 절대값을 모두 합하여 하나의 지표를 설정하는 방식이다.
* L2 distance (Euclidean Distance)
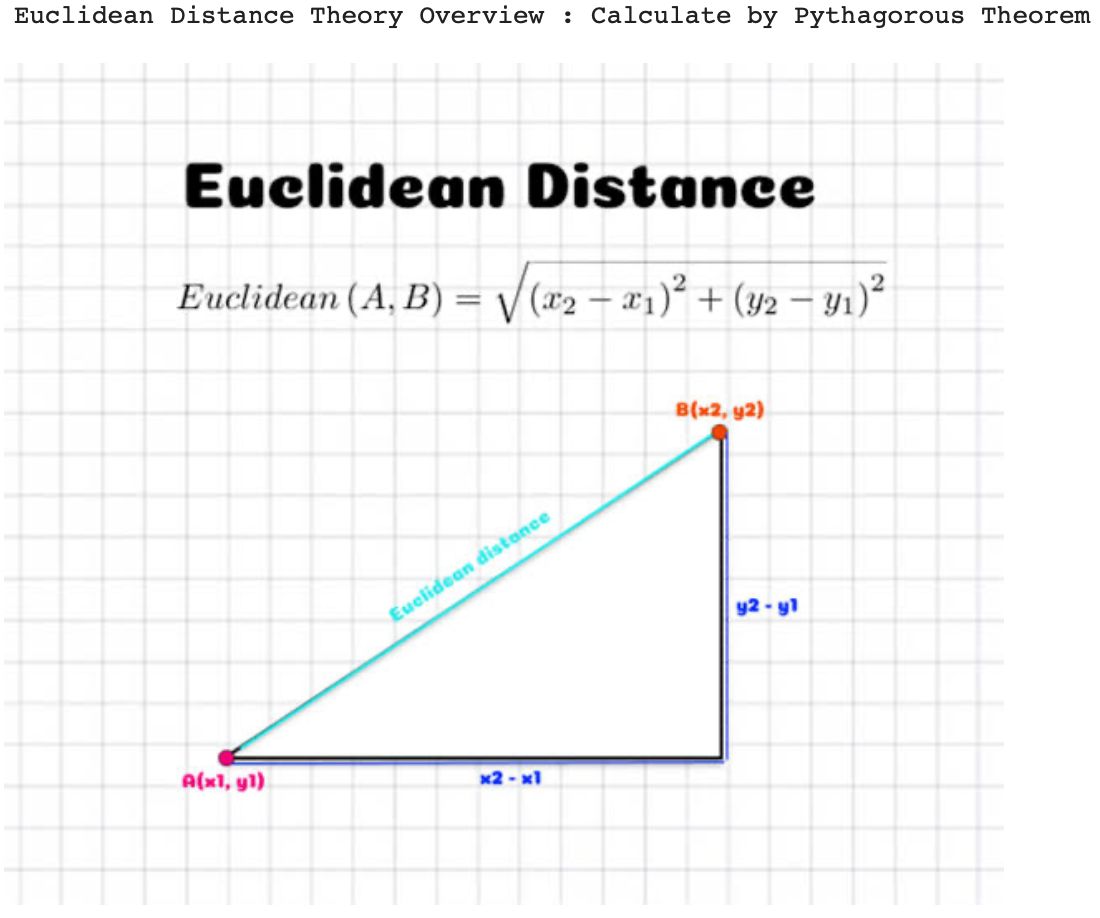
import numpy as np
class NearestNeighbor:
def __init__(self):
pass
# Memorize training data (just remembers all the training data)
def training(self, X, y):
self.xtr = X # X : matrix (N x D)
self.ytr = y # y : matrix (1 x N)
def predict(self, X):
num_test = X.shape[0]
Ypred = np.zeros(num_test, dtype = self.ytr.dtype)
for i in xrange(num_test):
# using the L1 distance
# -> for each test image, find closet train image
distances = np.sum(np.abs(self.xtr - X[i,:]), axis = 1)
min_index = np.argmin(distances)
Ypred[i] = self.ytr[min_index]
return Ypred
위 코드를 보면 numpy 라이브러리를 사용하여 코드를 간편하게 사용할 수 있다.
Training 함수를 거쳐서 Predict 함수에서 실제 가장 nearest한 데이터들을 찾아내게 된다.
하지만 이러한 NN(Nearest Neighbor) 방식에는 큰 단점이 존재하며 이는 Training 시간보다 Predict 시간이 훨씬 오래 걸린다는 것이다.
컴퓨터의 경우 예를 들어 100,000개의 사진 데이터가 존재한다고 했을 때, 단순하게 외우는 Training 과정을 그리 오래 걸리진 않을 것이다. 하지만 해당 사진들을 가지고 각종 연산 (위에서 언급한 L1 distance와 같이) 처리를 하는 Predict 시간이 훨씬 더 소요될 수 밖에 없다. 뿐만 아니라 class 분류에도 오류가 많아서 단순하게 픽셀 값을 비교하는 것만으로는 흰색 강아지와 멀리서 찍은 흰색 말의 형태가 비슷하다면, 이를 같은 '강아지' label에 분류할 수도 있게 된다.
1. Nearest Neighbor
-> training / predicting label을 나누어서 진행.
-> 아래와 같이 가장 왼쪽의 테스트 이미지와 유사한 순으로 학습 데이터를 정렬

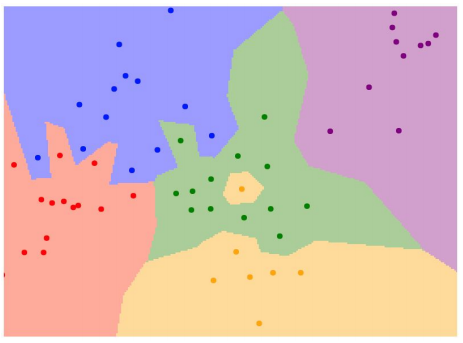
위 그림은 NN을 이용한 decision regions를 그림으로 그려본 것이다. NN을 사용할 경우 녹색 한가운데 노란색 영역이 있는 오류가 나타난다던가, 초록색 영역에서 파란색 영역을 침범하는 구간이 생기는 등 decision boundary가 robust하지 않게 된다.
2. K-Nearest Neighbor
위의 NN 방식에서 보완점으로 나온 것이 K-NN 방식이다.
해당 방식은 가장 가까운 이웃을 찾는 방식을 넘어서, 가까운 K개의 이웃을 찾고, 이 중 투표를 통해 가장 많은 레이블로 예측하고자 하는 것이다.
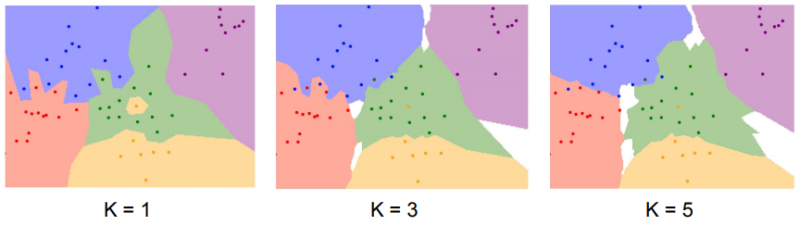
K가 증가함에 따라 Boundary가 점점 Robust 해지는 것을 확인할 수 있다.
http://vision.stanford.edu/teaching/cs231n-demos/knn/
http://vision.stanford.edu/teaching/cs231n-demos/knn/
vision.stanford.edu
* Hyper Parameter
KNN을 사용할 때 우리가 사용하려는 거리 척도, K값 같은 것들은 Hyper Parameter라고 하며, 이는 따로 학습되어지는 것이 아니라 사람이 직접 정해야한다.
그렇다면 해당 수치는 어떠한 기준으로 정하는걸까?
정답부터 말하자면, 지속적으로 테스트를 통해서 얻어내야 한다. 하지만 어떻게 테스트를 할 것인가에 대한 방법은 존재한다.
강의에서는 하지 말아야될 방법들을 소개하면서 최종적으로 아래의 방법을 설명했기에 다음 방법만 기술한다.

=> 해당 방법은 데이터들을 3개로 분류하는 것이다.
각각 train set, validation set, test set.
여러 Hyper Parameter 값들로 Train 데이터들을 학습시키고, validtaion set으로 이를 검증한다.
Validation set에서 가장 결과 값이 좋았던 Hyper Parameter 값들을 적용시켜 딱 한번만 Test set을 수행한다.
이때 train, validation, test set들은 random하게 지정하는 것이 좋다.
특히 시간 차를 두고 수집되는 데이터의 경우, 이전 데이터들만 train 최근 데이터들은 test set으로 지정하게 된다면 가장 결과 값이 좋은 Hyper Parameter를 찾는데 어려움이 생기게 된다.
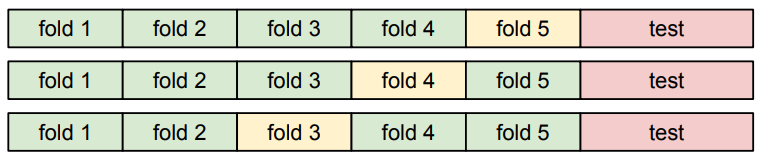
=> 위 방법의 보완책으로 cross validation 또한 존재하나, 이는 학습하는데 시간과 돈이 많이 들어가는 딥 러닝에서는 많이 채택되지는 않는 방법이다.

=> 위와 같이 Hyper Paramter 중 일부인 'K' 값을 조정하면서 나타나는 정확도 그래프이다. 이중 가장 수치가 좋았던 K 값을 최종적으로 Test Set에 사용하게 된다.
~~ 그러나 KNN 또한 이미지 분류에 잘 사용되지는 않는다.
왜냐면 L1, L2 distance가 이미지 간 거리 척도로 적절하지 않기 때문에 분명 다른 그림임에도 불구하고 거리만을 계산하여 같은 그림이라고 인식되는 경우도 있음. + 고차원의 이미지의 경우 충분한 트레이닝 샘플을 모으는 것이 현실적으로 불가능하다.
=========== =========== =========== =========== =========== =========== =========== ===========
## Linear Classfication
NN(Neural Network)와 CNN의 기반이 되는 알고리즘이다.
Parametric model (모수적 모델)의 기초가 되는 개념.
| In a parametric model, you know which model exactly you will fit to the data, e.g., linear regression line. In a non-parametric model, however, the data tells you what the 'regression' should look like. Let me give some concrete examples. Parametric Model: yi=β0+β1xi+eiyi=β0+β1xi+ei Here you know what the regression will look like: a linear line. Non-Parametric Model: yi=f(xi)+eiyi=f(xi)+ei where f(.) can be any function. The data will decide what the function f looks like. Data will not tell you the analytic expression for f(.), but it will give you its graph given your data set. The reason why people say that there is inherently no difference between parametric and non-parametric regression is that the function f(.) can be perfectly approximated by an infinite-parameter model, which is parametric. |
<https://m.blog.naver.com/metahedge/221656924408>
- Parametric model
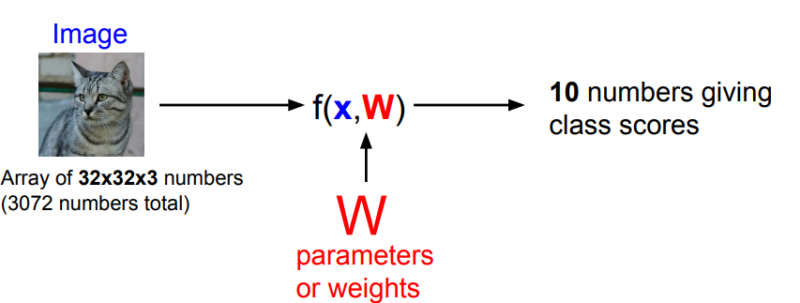
입력 이미지 x 와 파라미터(가중치) W 가 있는 함수
고양이 사진을 x라고 할 때, 함수 f는 x와 W 값을 가지고 10개의 숫자를 출력하게 된다. (CIFAR10 dataset을 이용한다고 친다)
이 때 숫자는 각 데이터셋의 클래스에 해당하는 스코어의 개념이다. 즉 고양이 스코어가 가장 높은 것이 '고양이'일 확률이 가장 큰 것이다.
Parametric model 접근법에서는 training data set의 데이터 정보를 요약해서 W 파라미터에 잘 저장하는 것이다.
따라서 테스트 소요 시간이 적게 걸리게 된다.
-> KNN의 경우 파라미터가 없어서 모든 Training Set을 test time에 사용했기에 테스트 소요 시간이 길다.
해당 W를 잘 설계하는 것, 즉슨 함수 f 를 잘 설계하는 것이 바로 딥러닝에서의 좋은 함수인 것이다.
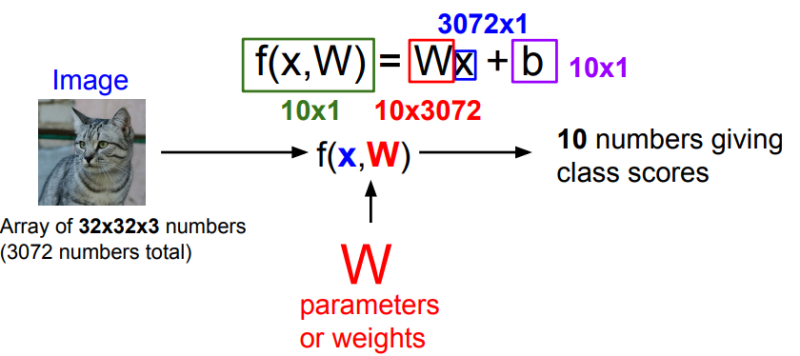
위의 그림에 대해서 완벽하게 이해는 하지 못했다,
이해한 바로는 입력 이미지가 (32*32*3) -> 3은 RGB 값이기에 3으로 설정
위 이미지를 하나의 벡터로 피게 되면 x는 (3072*1) 이 된다.
f=Wx+b 이기에 W는 10*3072이 되며, 그렇기에 결론적으로 10*1의 스코어를 가져다 줄 수 있다.
* b는 Bias를 의미하며, 이는 데이터와 무관하게 특정 클래스에 scaling offsets을 추가해줄 수 있는 것이다.
이 때 함수 f(x,W)가 직선의 방정식이라서 linear classifier라고 불리게 된다.
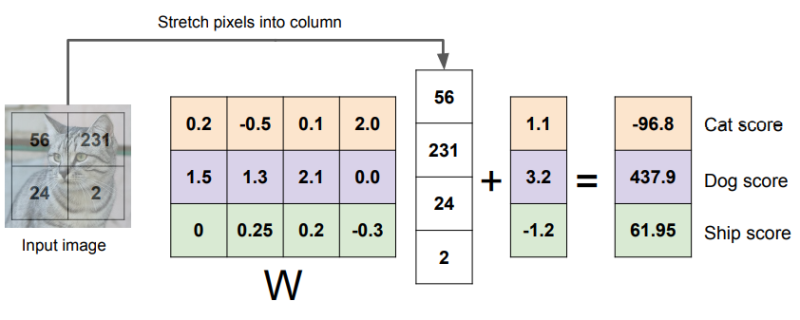
예시로 input 사진은 고양이, output은 각각 cat,dog,ship에 대한 스코어가 되게 된다.

이미지 자체를 고차원 공간에서 하나의 점이라고 인식한다면, Linear Classifier는 아래와 같이 각 클래스를 구분시켜주는 linear boundary 역할을 하게 된다.

=> 하지만 2,3번째 그림과 같이 데이터의 분포가 직선만으로는 절대 나뉠 수 없는 경우가 생긴다. 그렇기 때문에 여러 층의 신경망을 쌓게 되는 것이다.
+ multimodal problem : 각 종류의 데이터 특징에 따라 데이터 공간의 차원이 높아지기에, 차원의 저주(curse of dimensionality)가 일어나서 결국 성능저하가 일어나기 쉽다
'Nvidia > CS231n' 카테고리의 다른 글
| CS231n 7강 (2) | 2024.01.05 |
|---|---|
| CS231n 6강 (1) | 2023.12.19 |
| CS231n 5강 (1) | 2023.12.15 |
| CS231n 4강 (0) | 2023.12.11 |
| CS231n 3강 (0) | 2023.12.07 |