
Hadoop은 High Availability Distributed Object Oriented Platform의 약자이며, 고가용성 분산형 객체 지향적 플랫폼을 의미한다.
빅데이터 시장에서 절대적인 입지를 가지며, 하둡 에코시스템 생태계를 통해 빅데이터를 효율적으로 관리할 수 있게 되었다.
빅데이터 솔루션인 Hadoop 시장은 현재도 급성장하고 있으며, 비정형 데이터를 효과적으로 처리하는 오픈소스 빅데이터 솔루션이라는 특성으로 인해 많은 사랑을 받고 있다.
(참조: https://m.blog.naver.com/acornedu/222069158703)
==========================================================================================
기존 DB 시장은 데이터를 처리하기 위해 RDBMS 형태를 취하며 SQL문을 통해 데이터를 처리하는 것이 대부분이었다.
그러나 최근들어 엄청난 양의 비정형 데이터(사진,동영상,음원파일 등등)들이 생겨나기 시작했고, 이에 대한 데이터 저장 관련 수요가 높아졌다.
위와 같은 수요를 충족시키기 위해 다음과 같은 개념들이 나타났다.
1. NoSQL
- 스키마, 복잡한 관계형 구조 등을 짜지 않고 편하게 문서형 데이터를 저장할 수 없을까에 대한 수요 충족하기 위한 기술
- 대표적 예시> key-value DB,
2. Hadoop
- 빅데이터 저장시스템. 대용량 데이터 처리를 위한 분산처리 프레임워크.
- 한대의 컴퓨터로는 저장하거나 연산하기 어려운 규모의 거대 데이터를 여러 대의 컴퓨터로 나눠서 일을 처리하기 위함.
- 분석 시 나눠서 데이터를 분석한 이후 합치면 되기 때문에 속도 면에서는 장점을 가지고 있으나, 저장된 데이터 변경이 불가능하고, 신속한 작업에서는 부적합하다는 한계가 있다.
- 정형/비정형 데이터 모두 사용 가능하다.
==========================================================================================
# Hadoop 핵심 기술 2가지
1. HDFS (Hadoop Distributed File System)
- Hadoop 프레임워크를 위해 Java 언어로 작성된 분산 확장 파일 시스템.
- 여러 기계에 대용량 파일들을 나누어서 저장하는데, 데이터들을 여러 서버에 중복해서 저장하는 역할
2. MapReduce
- HDFS에 분산저장된 데이터들을 분산처리하는 기술
- 하나의 큰 데이터를 여러 개의 조각으로 나누어 처리하는 Map 단계
- 처리된 결과를 하나로 모아서 취합한 후 결과를 도출하는 Reduce 단계
==========================================================================================
# Hadoop EcoSystem
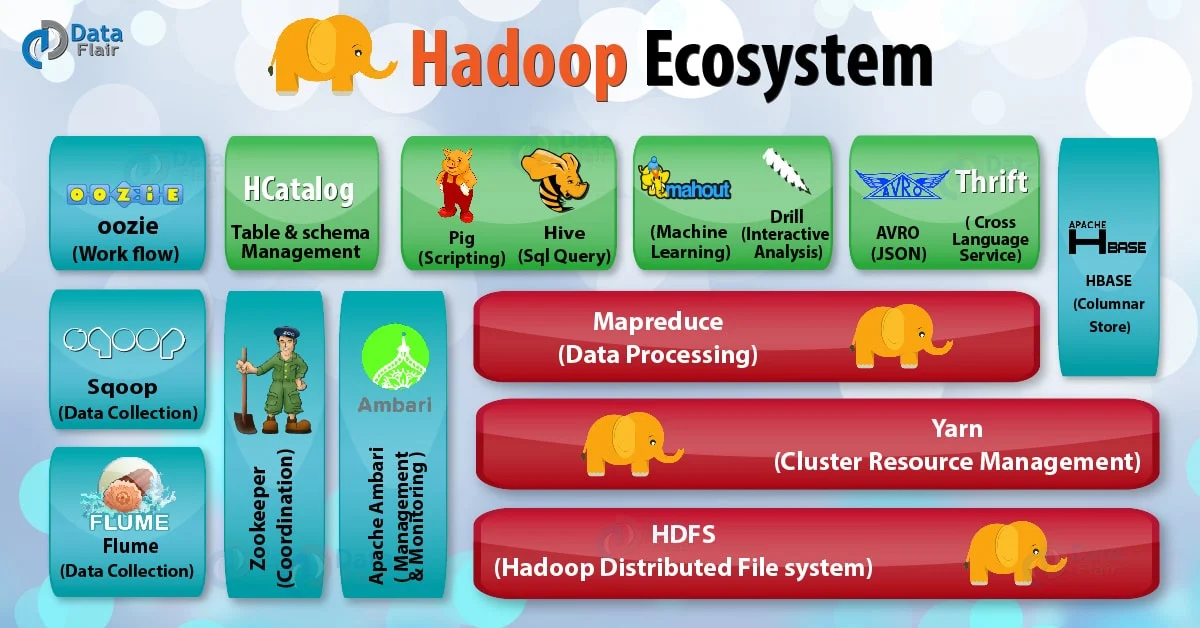
위에서 언급된 HDFS, MapReduce 외에도 Hadop에서 데이터를 분석 유지 저장 관리할 때 필요한 모든 것들을 Ecosystem이라고 한다.
- Hadoop core project : HDFS, Mapreduce
- Hadoop sub project : 그 외 나머지 (데이터 마이닝, 분석, 수집 등을 담당함)
'개인 공부' 카테고리의 다른 글
| LLM을 이용한 점검유지보수 자동화 (0) | 2024.06.14 |
|---|---|
| 2023 하반기 목표 프로젝트 (zabbix~weblogic 모니터링 및 slack 연동) (0) | 2023.08.09 |
| DeadLock (0) | 2023.05.25 |
| 공부 커리큘럼 (0) | 2022.07.01 |
| 궁금증 - 카카오톡은 어떻게 작동할까? (0) | 2022.04.15 |